가상 머신은 하드웨어의 제약을 뛰어넘어 여러 환경에서 동일한 운영체제를 사용하게 하지만, 사실 그 자체로는 기술이라기보단 어떤 컨셉에 가깝습니다. 하이퍼바이저(hypervisor)가 바로 가상 머신을 현실에 구현하는 그 기술이죠. 이번 글에서는 하이퍼바이저에 대해 알아봅니다.
가상 머신의 관리자
가상 머신을 만들고 관리하는 소프트웨어를 하이퍼바이저1라 부른다. VMM(Virtual Machine Monitor)이라고도 부르며, 물리 하드웨어와 게스트 OS2 사이에서 중재자 역할을 한다. 하이퍼바이저의 핵심 역할은 각 VM에 가상 하드웨어를 제공하고, 여러 VM이 물리 자원을 안전하게 공유하도록 조율하는 것이다.


하이퍼바이저는 동작하는 계층에 따라 세 가지 유형으로 나뉜다.
Type 0: 펌웨어 하이퍼바이저
Type 0 하이퍼바이저3는 하드웨어 펌웨어 자체에 가상화 기능이 내장된 형태다. 소프트웨어 하이퍼바이저가 등장하기 훨씬 이전부터 메인프레임과 엔터프라이즈 서버에서 사용되어 왔다.
Type 0의 핵심 아이디어는 물리 하드웨어를 펌웨어 수준에서 여러 파티션으로 분할하여, 각 파티션이 독립된 물리 머신처럼 동작하도록 만드는 것이다. Type 1/Type 2가 소프트웨어적으로 하드웨어를 시분할time-sharing하여 VM 간 자원을 공유하는 방식이라면, Type 0는 하드웨어를 공간 분할space partitioning하여 각 파티션에 CPU 코어, 메모리 영역, I/O 슬롯을 전용으로 배정한다. 자원을 공유하지 않으므로 파티션 간 간섭이 원천적으로 차단되며, 격리 수준이 가장 높다.
대표적인 구현으로는 IBM POWER의 LPAR4(펌웨어가 논리적 파티션을 생성함), Oracle SPARC의 LDOM, IBM 메인프레임의 PR/SM이 있다. Type 0는 특정 벤더의 특정 하드웨어에서만 동작하므로 이식성이 없지만, 하드웨어 수준의 격리가 제공하는 신뢰성 때문에 금융·의료·정부 분야의 미션 크리티컬 시스템에서 여전히 널리 사용된다.
Type 1: 베어메탈 하이퍼바이저
Type 1 하이퍼바이저는 하드웨어 바로 위에서 실행된다. 호스트 운영체제 없이 하이퍼바이저 자체가 하드웨어를 직접 제어하므로, 성능 오버헤드가 적고 보안성이 높다. 데이터센터와 클라우드 환경에서 주로 사용된다.
대표적인 예로는 VMware ESXi, Microsoft Hyper-V, Xen, 그리고 Linux KVM5이 있다.
Type 2: 호스팅 하이퍼바이저
Type 2 하이퍼바이저는 일반 운영체제(호스트 OS) 위에서 하나의 애플리케이션으로 실행된다. 호스트 OS의 자원 관리 기능을 활용하므로 설치와 사용이 간편하지만, 호스트 OS를 거쳐야 하므로 Type 1보다 성능 오버헤드가 크다. 개인 개발 환경이나 테스트 용도에 주로 사용된다.
대표적인 예로는 VMware Workstation, Oracle VirtualBox, Parallels Desktop이 있다.
KVM(Kernel-based Virtual Machine)은 리눅스 커널 모듈 형태로 구현되어, 리눅스 커널 자체를 하이퍼바이저로 변환한다. 리눅스라는 범용 OS 위에서 동작하므로 Type 2로 분류하기도 하지만, 커널 수준에서 하드웨어를 직접 제어하므로 성능 특성은 Type 1에 가깝다. 이런 이유로 KVM을 하이브리드 또는 Type 1에 가까운 구현으로 보는 시각이 일반적이다(Tanenbaum and Bos, 2023).
하이퍼바이저의 핵심 역할
하이퍼바이저의 핵심 역할은 물리 하드웨어를 여러 가상 머신이 안전하게 공유하도록 중재하는 것이며, 이를 위해 네 가지 서브시스템을 운영한다.
| 서브시스템 | 역할 | 대응하는 OS 개념 |
|---|---|---|
| VCPU 관리 | 게스트의 가상 CPU를 물리 CPU에 매핑하고 스케줄링 | 스케줄러 |
| 메모리 관리 | 게스트의 물리 주소를 실제 물리 주소로 변환 | 메모리 가상화 |
| I/O 중재 | 게스트의 디바이스 접근을 가로채 실제 하드웨어로 중계 | 디바이스 드라이버 |
| 인터럽트 라우팅 | 물리 인터럽트를 올바른 게스트에 전달 | 인터럽트 핸들러 |
운영체제가 프로세스에게 CPU와 메모리의 독점 사용이라는 환상을 제공하듯이 하이퍼바이저는 가상 머신에 컴퓨터 전체의 독점 사용이라는 환상을 제공한다. 차이가 있다면 환상의 범위가 프로세스 하나에서 운영체제 전체로 확대된다는 것이다.
가상 머신의 생애 주기
가상 머신을 실제로 구현하기 위해서는 가상 머신을 담을 자료구조가 필요한데 그중 대표적인 예시가 바로 VMCS(Virtual Machine Control Structure)다. VMCS가 생성되고, 사용되고, 소멸되는 전체 과정을 추적하며 가상 머신이 실제로 어떻게 구현되어 있는지 뜯어보자.
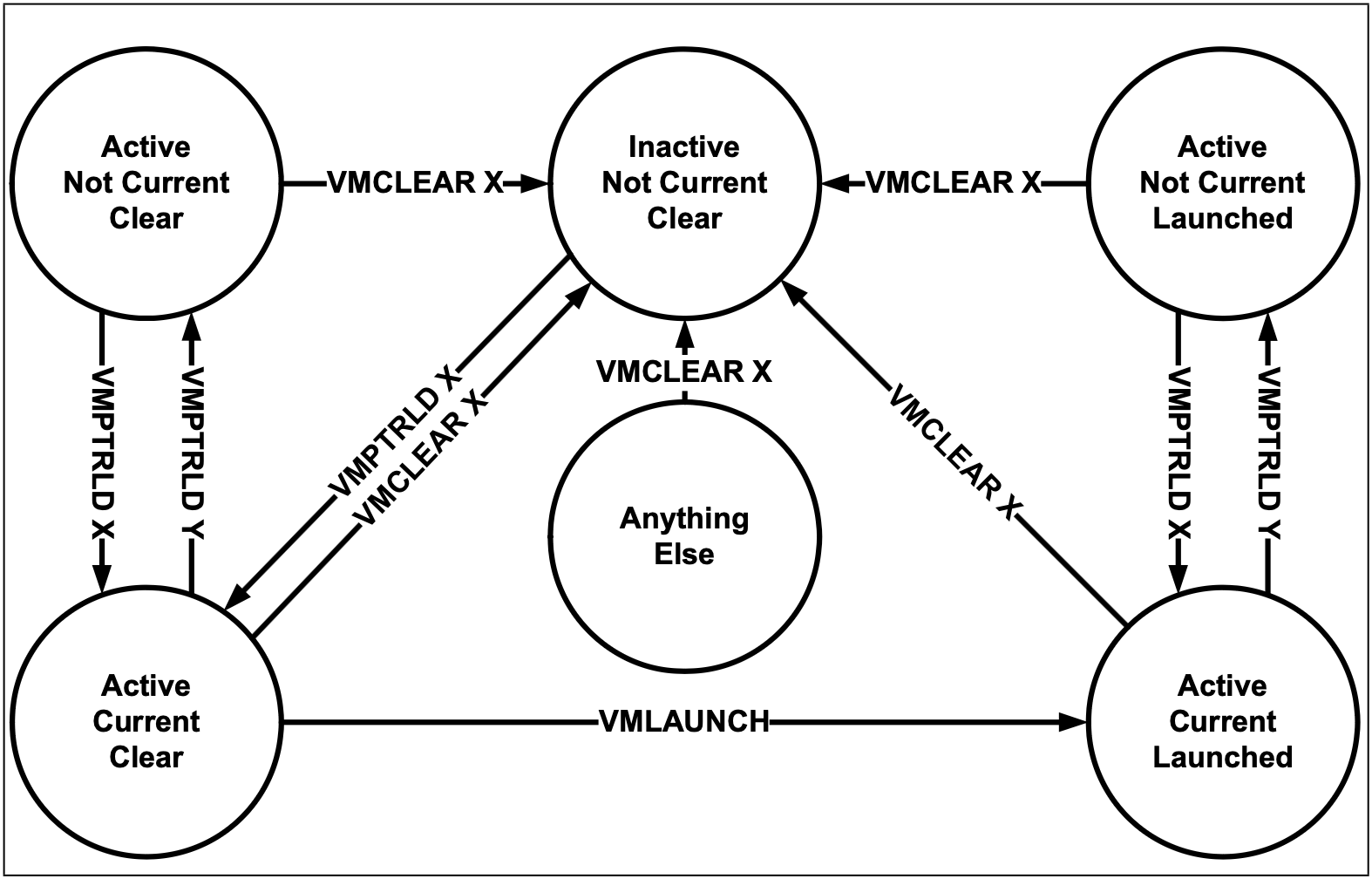
VMX 모드 진입
하드웨어 가상화를 사용하려면 먼저 CPU의 VMX(Virtual Machine Extensions) 모드를 활성화해야 한다. 하이퍼바이저가 VMXON 명령어를 실행하면, CPU는 루트 모드VMX root operation로 진입한다. 이 시점부터 CPU는 루트/비루트 두 가지 실행 모드를 지원하게 된다.
VMCS 생성과 초기화
각 가상 CPU(VCPU)6마다 하나의 VMCS가 필요하다. VMCS의 생성은 두 단계로 이루어진다.
VMCLEAR7 명령어는 지정된 메모리 영역을 깨끗한 VMCS로 초기화한다. 이어서 VMPTRLD8 명령어가 해당 VMCS를 현재 CPU의 "활성 VMCS"로 지정한다. 하나의 물리 CPU에서 동시에 활성화할 수 있는 VMCS는 하나뿐이므로, 다른 VCPU로 전환하려면 VMPTRLD로 VMCS를 교체해야 한다.
VMCS가 활성화되면 하이퍼바이저는 VMWRITE 명령어로 내부 필드를 설정한다. VMCS는 크게 여섯 영역으로 구성된다.
| 영역 | 내용 |
|---|---|
| 게스트 상태 영역 | 게스트의 레지스터, CR3, 세그먼트 셀렉터 등 (VM Entry 시 CPU에 로드됨) |
| 호스트 상태 영역 | 하이퍼바이저의 레지스터, CR3 등 (VM Exit 시 CPU에 로드됨) |
| VM 실행 제어 필드 | 어떤 이벤트가 VM Exit를 유발할지 설정 (예: I/O 접근, MSR 접근, 인터럽트 등) |
| VM Exit 제어 필드 | VM Exit 시 저장할 상태와 동작 방식 설정 |
| VM Entry 제어 필드 | VM Entry 시 복원할 상태와 동작 방식 설정 |
| VM Exit 정보 필드 | VM Exit 발생 원인, 관련 데이터 등 (읽기 전용, 하이퍼바이저가 원인 분석에 사용) |
이 구조를 Context Switch의 task_struct와 비교하면 이해가 쉽다. task_struct가 프로세스의 레지스터 상태, 스케줄링 메타데이터, 메모리 정보를 담고 있듯, VMCS는 가상머신의 CPU 상태, 전환 조건, 메모리 매핑 정보를 담고 있다. 다만 task_struct는 소프트웨어 자료구조인 반면, VMCS는 CPU 하드웨어가 직접 읽고 쓰는 자료구조라는 점이 다르다.
게스트 실행
VMCS 설정이 완료되면 VMLAUNCH9 명령어로 게스트를 최초 실행한다. 이후 VM Exit가 발생하여 하이퍼바이저로 돌아온 뒤 다시 게스트를 실행할 때는 VMRESUME10을 사용한다. 이 두 명령어의 차이는 VMCS의 런치 상태launch state 플래그에 있다. VMLAUNCH는 "clear" 상태에서만, VMRESUME은 "launched" 상태에서만 동작한다.


VMX 모드 종료
가상머신이 더 이상 필요 없으면, VMCLEAR로 VMCS를 정리하고 VMXOFF로 VMX 모드를 빠져나온다. 이 시점에서 CPU는 일반적인 실행 모드로 돌아간다.
VM Exit: 하이퍼바이저의 심장
VM Exit는 하이퍼바이저가 동작하는 핵심 메커니즘이다. 게스트가 비루트 모드에서 실행되다가, 하이퍼바이저의 개입이 필요한 이벤트가 발생하면 CPU가 자동으로 루트 모드로 전환한다. 이 과정에서 일어나는 일을 단계별로 살펴보자.
VM Exit 처리 흐름


①부터 ④까지는 하드웨어가 수행하는 부분이다. 게스트의 범용 레지스터, RIP, RSP, RFLAGS, CR3 등이 VMCS의 게스트 상태 영역에 자동 저장된다. 동시에 VMCS의 호스트 상태 영역에서 하이퍼바이저의 레지스터가 복원된다. 이 과정은 컨텍스트 스위치에서 pt_regs에 레지스터를 저장/복원하는 것과 유사하지만, 전환의 범위가 더 넓다. 단순히 레지스터뿐 아니라 CR3(페이지 테이블), 세그먼트 레지스터, MSR 일부까지 전환된다.
⑤부터 ⑧ 소프트웨어가 수행하는 부분이다. 하이퍼바이저는 VMCS의 VM Exit 정보 필드에서 Exit Reason11을 읽어 무엇이 VM Exit를 유발했는지 파악한다. 원인에 따라 적절한 에뮬레이션을 수행한 뒤, VMRESUME으로 게스트를 재개한다.
VM Exit의 주요 유형
| Exit Reason | 원인 | 하이퍼바이저의 처리 |
|---|---|---|
| I/O 명령어 | 게스트가 IN/OUT 실행 | 가상 디바이스 에뮬레이션 후 결과 반환 |
| MSR 접근 | 게스트가 RDMSR/WRMSR 실행 | 허용된 MSR이면 통과, 아니면 에뮬레이션 |
CR 접근 | 게스트가 CR0/CR3/CR4 변경 | 섀도우 값 업데이트, 필요시 EPT 동기화 |
| 외부 인터럽트 | 물리 하드웨어에서 인터럽트 발생 | 호스트 인터럽트 핸들러 실행 후 복귀 |
HLT | 게스트 CPU가 유휴 상태 진입 | VCPU를 디스케줄링하여 물리 CPU 양보 |
| EPT 위반 | GPA→HPA 매핑 없음 | 메모리 매핑 업데이트 (지연 할당lazy allocation) |
CPUID | 게스트가 CPU 정보 조회 | 가상화된 CPU 정보 반환 (기능 마스킹) |
| 트리플 폴트 | 게스트 커널 크래시 | VM 강제 종료 또는 리셋 |
VM Exit의 비용
VM Exit/Entry 한 사이클에는 약 5002,000 CPU 사이클이 소요된다(Intel SDM). 현대 CPU에서 이는 대략 0.21μs에 해당하지만, VM Exit 처리 로직(에뮬레이션)까지 포함하면 실질적 비용은 수 μs까지 늘어날 수 있다.
이 비용 때문에 VMCS의 VM 실행 제어 필드를 세밀하게 설정해 꼭 필요한 이벤트만 VM Exit를 유발하도록 VM Exit 횟수를 최소화하는 것이 하이퍼바이저 성능 최적화의 핵심이다. 예를 들어 HLT Exit를 비활성화하면 게스트가 유휴 상태에 진입해도 VM Exit가 발생하지 않아 성능이 향상되지만, 그만큼 물리 CPU를 다른 VM에 양보할 기회를 잃게 된다.
I/O 가상화
CPU 가상화와 메모리 가상화는 하드웨어 지원(VT-x, EPT/NPT) 덕분에 네이티브에 가까운 성능을 달성했다. 그러나 I/O 가상화는 여전히 하이퍼바이저의 가장 큰 성능 병목이다. 네트워크 카드, 디스크 컨트롤러, GPU 같은 I/O 장치를 가상화하는 방법은 크게 세 가지로 나뉜다.
에뮬레이션
가장 단순한 방법은 I/O 장치 전체를 소프트웨어로 에뮬레이션하는 것이다. 게스트가 I/O 포트에 접근하면 VM Exit가 발생하고, 하이퍼바이저가 해당 장치의 동작을 소프트웨어로 시뮬레이션한다. QEMU12가 이 방식의 대표적 구현체다.
에뮬레이션의 장점은 호환성이다. 실제로 존재하지 않는 하드웨어도 흉내 낼 수 있으므로, 어떤 게스트 OS든 수정 없이 사용할 수 있다. 그러나 모든 I/O 연산마다 VM Exit가 발생하므로 성능이 크게 떨어진다.
반가상화 I/O
에뮬레이션의 성능 문제를 해결하기 위해 등장한 것이 virtio13다. 가상머신에서 다룬 반가상화의 I/O 버전이라 할 수 있다.
virtio의 핵심 아이디어는 실제 존재하는 하드웨어를 흉내 내는 대신, 가상화에 최적화된 가상 장치 인터페이스를 새로 설계하는 것이다. 게스트 OS에는 virtio 드라이버(프론트엔드)를, 하이퍼바이저에는 virtio 백엔드를 구현하여, 양쪽이 공유 메모리의 링 버퍼virtqueue14를 통해 직접 데이터를 주고받는다.


virtio는 에뮬레이션에 비해 VM Exit 횟수를 크게 줄인다. 여러 I/O 요청을 모아서 한 번에 전달하는 배칭(batching)이 가능하고, 불필요한 하드웨어 레지스터 에뮬레이션을 생략할 수 있기 때문이다. 대신 게스트 OS에 virtio 드라이버를 설치해야 한다는 단점이 있지만, 현대 리눅스 커널과 Windows 게스트 드라이버가 모두 virtio를 기본 지원하므로 실용적으로 큰 문제가 되지 않는다.
SR-IOV: 하드웨어가 직접 가상화하기
SR-IOV(Single Root I/O Virtualization)15는 I/O 가상화의 최종 진화 형태다. 물리 I/O 장치 자체가 여러 개의 가상 장치(VF, Virtual Function)를 하드웨어 수준에서 제공하여, 각 VF를 별도의 VM에 직접 할당할 수 있다.
| 에뮬레이션 | virtio | SR-IOV | |
|---|---|---|---|
| VM Exit 빈도 | 매 I/O마다 | 배칭으로 감소 | 거의 없음 |
| 성능 | 네이티브의 30~60% | 네이티브의 80~95% | 네이티브에 근접 |
| 게스트 수정 | 불필요 | virtio 드라이버 필요 | VF 드라이버 필요 |
| 라이브 마이그레이션 | 용이 | 용이 | 어려움16 |
| 유연성 | 높음 | 높음 | 낮음 (하드웨어 VF 수 제한) |
SR-IOV에서 물리 장치가 VM에 직접 매핑되려면 DMA(Direct Memory Access)가 하이퍼바이저의 통제 아래 이루어져야 한다. 이를 위해 IOMMU17(Intel VT-d, AMD-Vi)가 DMA 주소를 GPA에서 HPA로 변환하며, 한 VM의 DMA가 다른 VM의 메모리를 침범하지 못하도록 격리한다.
Xen 아키텍처
Xen18은 2003년 케임브리지 대학에서 시작된 Type 1 하이퍼바이저로, 아마존 AWS의 초기 클라우드 인프라를 지탱한 기술이다. Xen의 가장 독특한 설계적 특징은 하이퍼바이저를 최대한 작게 유지하고, 나머지 기능을 특권 VM에 위임한다는 것이다.
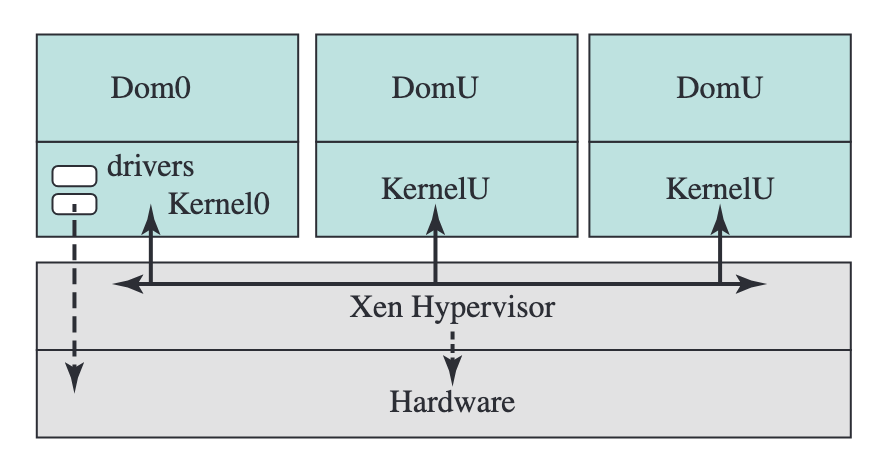
Dom0와 DomU
Xen에서 모든 게스트 OS는 도메인(domain)이라 불린다. 그 중 특별한 역할을 맡는 도메인이 Dom019이다.


Xen 하이퍼바이저 자체는 VCPU 스케줄링, 메모리 격리, 접근 제어만 담당하는 마이크로커널20에 가까운 설계다. 디바이스 드라이버는 하이퍼바이저 안에 없다.
Dom0는 하이퍼바이저가 부팅 시 가장 먼저 실행하는 특권 도메인으로, 모든 물리 디바이스 드라이버를 보유하고 다른 VM(DomU)의 I/O를 중재한다. Dom0가 없으면 Xen은 하드웨어와 소통할 수 없다.
DomU(일반 게스트)는 I/O 프론트엔드 드라이버만 갖고 있으며, 실제 I/O는 공유 메모리 링shared ring을 통해 Dom0의 백엔드 드라이버에 위임한다. 이 구조를 스플릿 드라이버 모델split driver model21이라 부른다.
이 설계의 장점은 하이퍼바이저의 공격 표면attack surface이 극도로 작다는 것이다. 디바이스 드라이버 버그(커널 버그의 가장 흔한 원인)가 하이퍼바이저를 직접 위협하지 않는다. 단점은 모든 DomU의 I/O가 Dom0를 거쳐야 하므로, Dom0가 병목이 될 수 있다는 점이다.
KVM 아키텍처
KVM(Kernel-based Virtual Machine)5은 Xen과 정반대의 설계 철학을 취한다. 리눅스 커널 자체를 하이퍼바이저로 변환하여, 커널이 수십 년간 축적한 스케줄러, 메모리 관리자, 디바이스 드라이버를 그대로 재사용한다.
KVM + QEMU 분업 구조


kvm.ko 커널 모듈은 /dev/kvm22 장치 파일을 노출하고, CPU 가상화(VT-x/AMD-V)와 메모리 가상화(EPT/NPT)를 담당한다. VMCS 관리, VM Exit 처리, EPT 구성이 모두 이 모듈 안에서 이루어진다.
QEMU는 사용자 공간 프로세스로, I/O 디바이스 에뮬레이션을 담당한다. 게스트의 I/O로 인해 VM Exit가 발생하면, KVM 모듈은 에뮬레이션이 필요한 경우 QEMU에 제어를 넘긴다. QEMU는 가상 네트워크 카드, 가상 디스크, 가상 그래픽 카드 등을 소프트웨어로 구현한다.
ioctl 인터페이스
QEMU와 KVM의 통신은 ioctl23 시스템 호출을 통해 이루어진다. 핵심 ioctl 명령어는 세 단계로 나뉜다.
| ioctl 대상 | 주요 명령어 | 역할 |
|---|---|---|
/dev/kvm | KVM_CREATE_VM | 새 VM 인스턴스 생성 |
| VM fd | KVM_CREATE_VCPU | VM에 VCPU 추가 |
| VM fd | KVM_SET_USER_MEMORY_REGION | 게스트 메모리 영역 등록 |
| VCPU fd | KVM_RUN | 게스트 실행 (VM Entry) |
KVM_RUN이 호출되면 KVM 모듈은 VMLAUNCH/VMRESUME을 실행하여 게스트로 진입한다. VM Exit가 발생하면 KVM이 처리할 수 있는 것(예: HLT, MSR 접근)은 커널 내에서 바로 처리하고, I/O 에뮬레이션이 필요한 것은 KVM_RUN의 반환 값으로 QEMU에 알린다. QEMU는 에뮬레이션을 수행한 뒤 다시 KVM_RUN을 호출하는 루프를 반복한다.
QEMU 메인 루프 (개념적 의사 코드):
┌──────────────────────────────┐
│ while (vm_running) { │
│ ioctl(vcpu_fd, KVM_RUN); │ ← VM Entry → 게스트 실행 → VM Exit
│ switch (run->exit_reason) {│ ← KVM이 기록한 Exit 원인 확인
│ case KVM_EXIT_IO: │
│ handle_io(run); │ ← I/O 에뮬레이션
│ case KVM_EXIT_MMIO: │
│ handle_mmio(run); │ ← MMIO 에뮬레이션
│ case KVM_EXIT_HLT: │
│ handle_halt(); │ ← VCPU 유휴 처리
│ } │
│ } │
└──────────────────────────────┘KVM의 강점: 커널 재사용
KVM의 가장 큰 강점은 리눅스 커널의 기존 서브시스템을 그대로 활용한다는 점이다.
각 VCPU는 리눅스 커널의 일반 스레드로 존재한다. 따라서 CFS/EEVDF 스케줄러가 VCPU를 물리 CPU에 배치하고, nice 값이나 cgroup으로 VM 간 CPU 자원을 분배할 수 있다. 별도의 하이퍼바이저 스케줄러를 만들 필요가 없다. 또한 게스트의 물리 메모리는 QEMU 프로세스의 가상 주소 공간에 매핑된다. 커널의 기존 메모리 관리자가 페이지 할당, 스왑, KSM(Kernel Same-page Merging)24 등을 투명하게 처리한다. 게다가 리눅스 커널에 이미 존재하는 수천 개의 디바이스 드라이버를 그대로 사용할 수 있다.
Xen vs KVM
| 항목 | Xen | KVM |
|---|---|---|
| 설계 철학 | 마이크로커널 — 최소한의 하이퍼바이저 | 모놀리식 — 리눅스 커널 = 하이퍼바이저 |
| I/O 모델 | 스플릿 드라이버 (Dom0 경유) | QEMU 에뮬레이션 + virtio |
| 스케줄러 | 자체 스케줄러 (Credit, Credit2, RTDS) | 리눅스 CFS/EEVDF 재사용 |
| 메모리 관리 | 자체 구현 (grant table, balloon) | 리눅스 MM 재사용 |
| 코드 규모 | 하이퍼바이저 약 15만 줄 | kvm.ko 약 5만 줄 (커널 전체는 수천만 줄) |
| 공격 표면 | 작음 (하이퍼바이저 최소화) | 큼 (리눅스 커널 전체) |
| 성능 | Dom0 경유 I/O 오버헤드 | 커널 직접 접근으로 낮은 오버헤드 |
| 생태계 | AWS (초기), Citrix | AWS (현재 Nitro), GCP, Azure, OpenStack |
오늘날 클라우드 시장에서는 KVM 기반 구현이 주류를 차지하고 있다. AWS도 초기에 Xen을 사용했으나, 2017년부터 KVM 기반의 Nitro 하이퍼바이저로 전환했다. KVM이 대세가 된 이유는 리눅스 생태계의 막대한 자산(드라이버, 도구, 커뮤니티)을 그대로 활용할 수 있다는 실용적 이점이 크기 때문이다. 다만 Xen의 마이크로커널 설계가 보안 측면에서 갖는 이론적 우위는 여전히 유효하며, Qubes OS 같은 보안 중심 시스템에서는 Xen이 여전히 사용된다.
출처
- Silberschatz, A., Galvin, P. B., and Gagne, G. (2018) Operating System Concepts. 10th ed. Hoboken, NJ: Wiley.
- Tanenbaum, A. S. and Bos, H. (2023) Modern Operating Systems. 5th ed. London: Pearson.
- Barham, P. et al. (2003) 'Xen and the Art of Virtualization', Proceedings of the 19th ACM Symposium on Operating Systems Principles (SOSP '03).
- Kivity, A. et al. (2007) 'kvm: the Linux Virtual Machine Monitor', Proceedings of the Linux Symposium.
- Bellard, F. (2005) 'QEMU, a Fast and Portable Dynamic Translator', Proceedings of the USENIX Annual Technical Conference.
- Russell, R. (2008) 'virtio: towards a de-facto standard for virtual I/O devices', ACM SIGOPS Operating Systems Review, 42(5), pp.95-103.
- Waldspurger, C. A. (2002) 'Memory Resource Management in VMware ESX Server', Proceedings of the 5th USENIX Symposium on Operating Systems Design and Implementation (OSDI '02).
- Intel Corporation. Intel® 64 and IA-32 Architectures Software Developer's Manual, Volume 3, Chapters 23-28.
- AMD. AMD64 Architecture Programmer's Manual, Volume 2, Chapter 15.
- PCI-SIG. Single Root I/O Virtualization and Sharing Specification, Revision 1.1.
- Intel Corporation. Intel Virtualization Technology for Directed I/O Architecture Specification.
- Linux kernel source v6.19 —
arch/x86/kvm/,drivers/virt/,Documentation/virt/kvm/. - Xen Project Documentation — https://wiki.xenproject.org/.
*[ACM]: Association for Computing Machinery *[AMD]: Advanced Micro Devices *[AWS]: Amazon Web Services *[CPU]: Central Processing Unit *[DMA]: Direct Memory Access *[EPT]: Extended Page Table *[IBM]: International Business Machines *[IOMMU]: I/O Memory Management Unit *[KSM]: Kernel Same-page Merging *[KVM]: Kernel-based Virtual Machine *[MSR]: Model-Specific Register *[PCI]: Peripheral Component Interconnect *[QEMU]: Quick Emulator *[SDM]: Software Developer's Manual *[VCPU]: Virtual CPU *[VM]: Virtual Machine *[VMCS]: Virtual Machine Control Structure *[VMX]: Virtual Machine Extensions *[VT]: Virtualization Technology
*[OS]: Operating System
Footnotes
-
하이퍼바이저(hypervisor)라는 이름은 슈퍼바이저(supervisor)(운영체제의 별명)를 관리하는 상위 개념이라는 뜻에서 유래했다. VMM(Virtual Machine Monitor)과 동의어로 사용된다. — Silberschatz, Galvin and Gagne (2018), §18.1. ↩
-
게스트 OSguest OS란 가상머신 위에서 실행되는 운영체제를 말한다. 이와 대비하여, 하이퍼바이저가 실행되는 기반 환경을 호스트(host)라 부른다. — Silberschatz, Galvin and Gagne (2018), §18.1. ↩
-
Type 0 하이퍼바이저라는 분류는 Silberschatz 등의 Operating System Concepts 10판에서 사용하는 용어로, 하드웨어 펌웨어 수준에서 가상화를 제공하는 시스템을 지칭한다. Type 1/Type 2와 달리 업계에서 보편적으로 통용되는 용어는 아니며, "펌웨어 기반 가상화" 또는 "하드웨어 파티셔닝"이라는 표현이 더 흔하게 사용된다. — Silberschatz, A., Galvin, P. B., and Gagne, G. (2018) Operating System Concepts. 10th ed., §18.4. ↩
-
LPAR(Logical Partitioning)은 IBM이 1999년 POWER 플랫폼에 도입한 펌웨어 기반 가상화 기술이다. PowerVM 펌웨어(PHYP)가 물리 자원을 논리적 파티션으로 분할하며, 각 파티션은 독립된 운영체제(AIX, Linux, IBM i)를 실행할 수 있다. Micro-Partitioning 모드에서는 하나의 물리 CPU 코어를 최대 10개의 가상 프로세서로 분할하여 시분할도 지원한다. — IBM, IBM PowerVM Virtualization Introduction and Configuration, SG24-7940. ↩
-
KVM(Kernel-based Virtual Machine)은 리눅스 커널 2.6.20(2007년)부터 포함된 가상화 모듈이다.
kvm.ko(공통 코드),kvm-intel.ko(Intel VT-x 지원),kvm-amd.ko(AMD-V 지원)의 세 모듈로 구성되며, 커널 모듈이 CPU 가상화를, QEMU가 I/O 장치 에뮬레이션을 담당하는 분업 구조로 동작한다. —Documentation/virt/kvm/; Kivity, A. et al. (2007) 'kvm: the Linux Virtual Machine Monitor', Proceedings of the Linux Symposium. ↩ ↩2 -
VCPU(Virtual CPU)는 물리 CPU를 가상화한 것으로, 하나의 물리 CPU 코어 위에서 여러 VCPU가 시분할로 실행된다. 각 VCPU는 독립된 VMCS를 가지며, 하이퍼바이저의 스케줄러에 의해 물리 코어에 배치된다. — Intel SDM Volume 3, §23.1. ↩
-
VMCLEAR는 지정된 VMCS의 런치 상태를 "clear"로 리셋하고, 캐시된 VMCS 데이터를 메모리에 기록하는 명령어다. VMCS를 다른 물리 CPU로 이동시키거나 초기화할 때 사용한다. — Intel SDM Volume 3, §24.11.3. ↩ -
VMPTRLD는 지정된 VMCS를 현재 물리 CPU의 "현재 VMCS"로 설정하는 명령어다. 이후VMREAD/VMWRITE명령어가 이 VMCS에 대해 동작한다. — Intel SDM Volume 3, §24.11.2. ↩ -
VMLAUNCH는 현재 VMCS의 게스트 상태를 CPU에 로드하여 비루트 모드로 전환하는 명령어다. VMCS의 런치 상태가 "clear"일 때만 사용할 수 있다. 실행 후 런치 상태는 "launched"로 변경된다. — Intel SDM Volume 3, §24.11.4. ↩ -
VMRESUME은VMLAUNCH와 동일한 동작을 수행하지만, 런치 상태가 "launched"일 때만 사용할 수 있다. VM Exit 이후 게스트를 재개할 때 사용한다. — Intel SDM Volume 3, §24.11.4. ↩ -
Exit Reason은 VMCS의 VM Exit 정보 필드 중 32비트 값으로, VM Exit를 유발한 원인을 나타내는 코드다. Intel SDM의 Appendix C에 전체 목록이 정의되어 있으며, 예를 들어 10은
CPUID, 12는HLT, 30은 I/O 명령어, 48은 EPT 위반에 해당한다. — Intel SDM Volume 3, Appendix C. ↩ -
QEMU(Quick Emulator)는 Fabrice Bellard가 2003년에 개발한 오픈소스 머신 에뮬레이터다. 단독으로는 동적 이진 변환을 통한 전체 시스템 에뮬레이션을 수행하지만, KVM과 결합하면 CPU 실행은 하드웨어가 직접 담당하고 QEMU는 I/O 에뮬레이션에 집중하여 거의 네이티브 수준의 성능을 달성한다. — Bellard, F. (2005) 'QEMU, a Fast and Portable Dynamic Translator', USENIX Annual Technical Conference. ↩
-
virtio는 Rusty Russell이 2008년에 제안한 반가상화 I/O 프레임워크다.
virtio-net(네트워크),virtio-blk(블록 스토리지),virtio-scsi(SCSI),virtio-gpu(그래픽) 등 다양한 장치 유형을 지원한다. 리눅스 커널 2.6.25부터 기본 포함되었다. — Russell, R. (2008) 'virtio: towards a de-facto standard for virtual I/O devices', ACM SIGOPS Operating Systems Review, 42(5), pp.95-103. ↩ -
virtqueue는 virtio 프론트엔드(게스트)와 백엔드(호스트) 간 데이터를 주고받는 공유 메모리 링 버퍼다. 디스크립터 테이블descriptor table, 가용 링available ring, 사용 완료 링used ring의 세 부분으로 구성된다. —
Documentation/driver-api/virtio/virtio.rst. ↩ -
SR-IOV(Single Root I/O Virtualization)는 PCI-SIG가 정의한 사양으로, 물리 장치(PF, Physical Function) 하나가 여러 경량 가상 장치(VF, Virtual Function)를 노출한다. 각 VF는 독립된 PCIe 구성 공간과 BAR(Base Address Register)을 가지며, IOMMU를 통해 VM에 직접 할당된다. — PCI-SIG, Single Root I/O Virtualization and Sharing Specification, Revision 1.1. ↩
-
SR-IOV 환경에서 라이브 마이그레이션이 어려운 이유는 VF가 특정 물리 장치에 종속되어 있기 때문이다. 마이그레이션 시 VF를 분리하고, virtio로 임시 전환한 뒤, 대상 호스트에서 새 VF를 할당하는 단계가 필요하다. — Kadav, A. and Swift, M. (2009) 'Live Migration with Pass-through Device for Linux VM', Ottawa Linux Symposium. ↩
-
IOMMU(Input/Output Memory Management Unit)는 I/O 장치의 DMA 요청에 대해 주소 변환과 접근 제어를 수행하는 하드웨어다. Intel의 VT-d(Virtualization Technology for Directed I/O)와 AMD의 AMD-Vi가 해당한다. IOMMU 없이 장치를 VM에 직접 할당하면, 악의적 게스트가 DMA로 다른 VM의 메모리를 읽을 수 있어 보안 격리가 무너진다. — Intel, Intel Virtualization Technology for Directed I/O Architecture Specification. ↩
-
Xen은 2003년 Barham 등이 발표한 오픈소스 Type 1 하이퍼바이저다. 현재 Linux Foundation 산하의 Xen Project로 유지보수되고 있다. — Barham, P. et al. (2003) 'Xen and the Art of Virtualization', SOSP '03. ↩
-
Dom0(Domain 0)는 Xen이 부팅 시 가장 먼저 실행하는 특권 도메인으로, 물리 하드웨어에 대한 직접 접근 권한을 갖는다. VM 생성/삭제, 디바이스 접근 중재, 하이퍼바이저 관리 인터페이스 제공을 담당한다. 일반적으로 리눅스나 NetBSD가 Dom0로 사용된다. — Xen Project Documentation, 'Dom0'. ↩
-
마이크로커널microkernel은 OS 커널을 최소한의 기능(IPC, 스케줄링, 메모리 관리)만 포함하도록 설계하고, 디바이스 드라이버와 파일 시스템 등을 사용자 공간 서비스로 분리하는 커널 아키텍처다. 대표적인 예로 L4, Mach, MINIX3가 있다. ↩
-
스플릿 드라이버 모델split driver model은 디바이스 드라이버를 프론트엔드(게스트 측)와 백엔드(Dom0 측)로 분리하여, 공유 메모리 링을 통해 통신하는 I/O 아키텍처다. Xen의 핵심 설계 패턴이며, virtio도 이 모델에서 영감을 받았다. — Barham, P. et al. (2003), §3. ↩
-
/dev/kvm은 KVM 커널 모듈이 노출하는 문자 장치 파일이다. 사용자 공간 프로그램(QEMU 등)이open()으로 연 뒤,ioctl()로 VM 생성, VCPU 생성, 메모리 매핑 등을 요청한다. —Documentation/virt/kvm/api.rst. ↩ -
ioctl(I/O control)은 유닉스 시스템에서 장치 드라이버에 장치 고유의 명령을 전달하는 시스템 호출이다.read()/write()로 표현하기 어려운 제어 명령에 사용된다. KVM은 이 메커니즘을 통해 사용자 공간에 가상화 API를 제공한다. —man 2 ioctl. ↩ -
KSM(Kernel Same-page Merging)은 리눅스 커널이 동일한 내용을 가진 메모리 페이지를 탐지하여 하나의 물리 페이지로 합치는 기능이다. 같은 OS를 실행하는 여러 VM이 동일한 커널 코드, 라이브러리를 공유하므로, KSM으로 상당한 메모리 절감이 가능하다. Copy-on-Write와 결합하여, 페이지가 수정되면 자동으로 분리된다. —
Documentation/admin-guide/mm/ksm.rst. ↩