소개글
사용자 프로그램은 하드웨어에 직접 접근할 수 없습니다. 파일을 읽거나, 네트워크 패킷을 보내거나, 새로운 프로세스를 생성하는 등 하드웨어와 관련된 모든 작업은 커널을 통해야만 합니다. 이때 사용자 프로그램이 커널에 서비스를 요청하는 인터페이스가 바로 시스템 호출System Call입니다. 이 글에서는 시스템 호출의 개념과 필요성, 동작 원리, 그리고 리눅스 커널에서의 구현까지를 살펴봅니다.
왜 시스템 호출이 필요한가
현대 운영체제는 CPU의 이중 모드dual mode1를 활용하여 커널과 사용자 프로그램을 분리한다. 사용자 모드user mode에서는 특권 명령어privileged instruction2를 실행할 수 없고, 하드웨어 자원에 직접 접근하는 것도 금지된다. 이 분리가 없다면 악의적이거나 버그가 있는 프로그램 하나가 디스크의 데이터를 파괴하거나, 다른 프로세스의 메모리를 침범하거나, 시스템 전체를 멈출 수 있다.
그런데 사용자 프로그램도 파일을 읽고, 네트워크로 데이터를 보내고, 새 프로세스를 만드는 등의 작업은 반드시 수행해야 한다. 이 모든 작업은 하드웨어 접근을 수반하므로 커널의 도움 없이는 불가능하다. 시스템 호출은 바로 이 간극을 잇는 통제된 관문이다. 사용자 프로그램이 시스템 호출을 통해 커널에 서비스를 요청하면, CPU는 커널 모드로 전환되어 커널 코드가 해당 작업을 대행한 뒤 결과를 반환한다. 사용자 프로그램이 직접 하드웨어를 건드리는 일은 없으므로, 시스템의 안정성과 보안이 유지된다.
트랩: 사용자에서 커널로 건너가는 메커니즘
시스템 호출을 이해하기 위해서는 먼저 CPU가 사용자 모드에서 커널 모드로 전환되는 과정을 이해해야 한다. 이 전환을 유발하는 이벤트를 통칭하여 트랩(trap)이라 부르며, 크게 세 가지 유형이 있다


- 시스템 호출은 사용자 프로그램이 의도적으로 유발하는 동기적 트랩이다. x86-64에서는
SYSCALL명령어, AArch64에서는SVC(Supervisor Call) 명령어가 이 역할을 한다. - 예외exception는 프로그램 실행 도중에 비의도적으로 발생하는 동기적 트랩이다. 0으로 나누기, 유효하지 않은 메모리 주소 접근(페이지 폴트page fault), 잘못된 명령어 실행 등이 여기에 해당한다.
- 인터럽트(interrupt)는 CPU 외부의 하드웨어 장치(타이머, 디스크 컨트롤러, 네트워크 인터페이스 등)가 비동기적으로 발생시키는 신호다. 현재 실행 중인 명령어와 무관하게 도착한다는 점이 앞의 두 유형과 다르다.
세 유형 모두 커널 모드로의 전환을 유발하지만, 시스템 호출만이 사용자 프로그램의 명시적 요청에 의한 것이다. 커널은 시작 시 트랩 테이블trap table을 설정하여 각 이벤트에 대한 핸들러 주소를 CPU에 등록해 둔다. x86-64에서는 이를 IDT(Interrupt Descriptor Table)3라 부르고, AArch64에서는 예외 벡터 테이블exception vector table(VBAR_EL1)이 같은 역할을 한다.
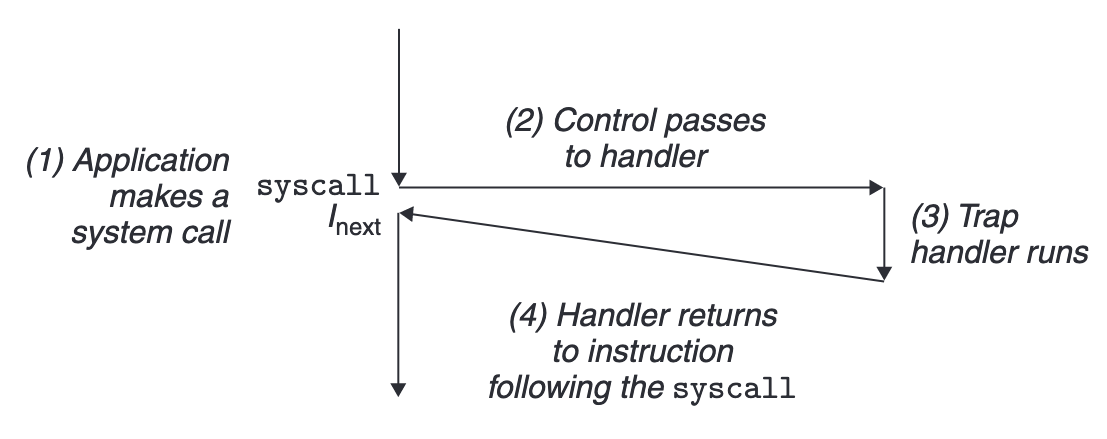
위 그림은 트랩의 기본 흐름을 보여준다. 애플리케이션이 시스템 호출을 요청하면(1), 제어가 트랩 핸들러로 넘어가고(2), 커널이 요청된 서비스를 처리한 뒤(3), 시스템 호출 다음 명령어()로 복귀한다(4).
시스템 호출의 동작 원리
호출 규약
사용자 프로그램이 시스템 호출을 요청할 때는, 어떤 서비스를 원하는지(시스템 호출 번호)와 그 서비스에 필요한 인자를 정해진 방식으로 전달해야 한다. 이를 시스템 호출 규약syscall convention이라 한다.
x86-64 리눅스에서는 RAX 레지스터에 시스템 호출 번호를, RDI, RSI, RDX, R10, R8, R9에 최대 6개의 인자를 넣은 뒤 SYSCALL 명령어를 실행한다. 반환값은 RAX에 담겨 돌아온다.4
AArch64 리눅스에서는 X8에 시스템 호출 번호를, X0~X5에 인자를 넣고 SVC #0 명령어를 실행한다. 반환값은 X0에 담긴다.
C 라이브러리의 래퍼 함수
실제로 프로그래머가 RAX에 번호를 넣고 SYSCALL을 직접 실행하는 일은 드물다. 대부분은 C 라이브러리(glibc, musl 등)가 제공하는 래퍼 함수wrapper function를 통해 시스템 호출을 사용한다.
// 프로그래머가 호출하는 코드
ssize_t n = write(fd, buf, count);프로그래머가 write()를 호출하면, C 라이브러리 내부에서는 다음과 같은 일이 일어난다.
- 시스템 호출 번호(x86-64에서
write는 1)를RAX에 저장한다. fd를RDI에,buf를RSI에,count를RDX에 저장한다.SYSCALL명령어를 실행하여 커널 모드로 진입한다.- 커널이 처리를 마치고 반환하면,
RAX의 반환값을 확인한다. - 반환값이 음수이면
errno를 설정하고 -1을 반환한다.
이 래퍼 덕분에 프로그래머는 아키텍처별 세부사항을 신경 쓰지 않고, 일반적인 함수 호출과 동일한 방식으로 시스템 호출을 사용할 수 있다.
커널 진입과 처리
SYSCALL 명령어가 실행되면 CPU 하드웨어가 다음 동작을 자동으로 수행한다.
- 현재
RIP를RCX에,RFLAGS를R11에 저장한다. LSTARMSR5에 저장된 주소를RIP에 로드한다. 이 주소가 커널의 시스템 호출 진입점(entry_SYSCALL_64)이다.CS와SS를 커널 모드 세그먼트로 변경하여 Ring 0으로 전환한다.
entry_SYSCALL_64에 도착한 커널 코드는 다음 절차를 밟는다.
- Per-CPU6 자료구조에서 커널 스택 포인터를 가져와 스택을 전환한다.7
- 사용자 레지스터를 커널 스택의
pt_regs구조체에 저장한다. RAX의 시스템 호출 번호를 검증한 뒤,sys_call_table[RAX]로 해당 서비스 함수를 호출한다.- 서비스 함수가 반환하면, 결과를
pt_regs의RAX위치에 기록한다. SYSRET(또는IRET)를 통해 사용자 모드로 복귀한다.


AArch64에서는 SVC #0 명령어가 동기 예외를 발생시키고, CPU가 SPSR_EL1에 프로그램 상태를, ELR_EL1에 복귀 주소를 자동으로 저장한 뒤 VBAR_EL1에 등록된 예외 벡터로 분기한다. 커널의 el0_svc 핸들러가 나머지 레지스터를 저장하고 시스템 호출 테이블을 조회하는 과정은 x86-64와 개념적으로 동일하다.
시스템 호출 테이블
커널이 수백 가지 시스템 호출 각각을 처리하기 위해 사용하는 디스패치 메커니즘이 시스템 호출 테이블system call table이다.
리눅스에서는 arch/x86/entry/syscalls/syscall_64.tbl에 시스템 호출 번호와 대응하는 커널 함수의 매핑이 정의되어 있고, 빌드 시 자동으로 sys_call_table 배열이 생성된다. 대표적인 시스템 호출과 그 번호를 살펴보면 다음과 같다(x86-64 기준).
| 번호 | 이름 | 커널 함수 | 기능 |
|---|---|---|---|
| 0 | read | ksys_read() | 파일 서술자에서 데이터 읽기 |
| 1 | write | ksys_write() | 파일 서술자에 데이터 쓰기 |
| 2 | open | do_sys_open() | 파일 열기 |
| 3 | close | close_fd() | 파일 서술자 닫기 |
| 57 | fork | kernel_clone() | 새 프로세스 생성 |
| 59 | execve | do_execveat_common() | 프로그램 교체 실행 |
| 60 | exit | do_exit() | 프로세스 종료 |
| 62 | kill | kill_something_info() | 시그널 전송 |
| 231 | exit_group | do_group_exit() | 스레드 그룹 전체 종료 |
시스템 호출 번호는 한번 배정되면 변경되지 않는다. 이는 사용자 공간과 커널 사이의 ABI(Application Binary Interface) 안정성을 보장하기 위한 리눅스의 근본 원칙이다. 새로운 시스템 호출은 항상 번호를 추가하는 방식으로만 도입된다.8
시스템 호출의 분류
POSIX9 표준을 기준으로, 시스템 호출은 기능에 따라 크게 다섯 범주로 분류된다(Silberschatz, Galvin and Gagne, 2018).
프로세스 제어
프로세스의 생성, 종료, 대기, 실행 제어에 관련된 시스템 호출이다. fork()로 프로세스를 복제하고, exec() 계열 함수로 새 프로그램을 로드하며, wait()으로 자식 프로세스의 종료를 기다리고, exit()으로 프로세스를 종료하는 것이 대표적이다. 프로세스 포스트에서 이 호출들의 실제 사용 예시를 다루고 있다.
파일 관리
파일의 생성, 삭제, 읽기, 쓰기, 위치 이동 등을 처리한다. open(), read(), write(), close(), lseek() 등이 이 범주에 속한다. 리눅스에서는 "모든 것이 파일이다"라는 철학에 따라, 소켓이나 파이프 같은 통신 채널도 파일 서술자를 통해 접근하므로 파일 관리 시스템 호출의 활용 범위가 매우 넓다.
장치 관리
하드웨어 장치에 대한 접근을 제어한다. ioctl()로 장치별 명령을 전달하고, mmap()으로 장치 메모리를 프로세스의 주소 공간에 매핑하는 등의 작업이 여기에 해당한다.
정보 유지
시스템이나 프로세스에 관한 정보를 조회하거나 설정한다. getpid()로 프로세스 ID를 확인하고, clock_gettime()으로 현재 시각을 조회하며, uname()으로 시스템 정보를 얻는 것이 대표적이다.
통신
프로세스 간 데이터 교환을 가능하게 한다. 파이프(pipe()), 소켓(socket(), connect(), sendto()), 공유 메모리(shmget(), shmat()), 시그널(kill(), sigaction()) 등이 이 범주에 속한다. 프로세스 간 통신의 구체적인 메커니즘은 IPC 포스트에서 다룬다.
SYSCALL vs 레거시 진입 경로
x86 아키텍처에서 시스템 호출 진입 방식은 시대에 따라 발전해 왔다.
INT 0x80 — 소프트웨어 인터럽트 (레거시)
32비트 리눅스에서 사용하던 방식으로, INT 0x80 명령어가 IDT의 128번 벡터를 통해 커널 핸들러로 분기한다. 이 방식은 인터럽트 처리의 전체 경로(IDT 조회 → 권한 검사 → 스택 프레임 구성)를 거치므로 느리다.
SYSENTER/SYSEXIT — 빠른 진입 (32비트 전용)
Intel이 Pentium II에서 도입한 전용 명령어 쌍으로, IDT를 우회하고 MSR에 미리 등록된 주소로 직접 분기한다. INT 0x80보다 훨씬 빠르지만, AMD의 SYSCALL/SYSRET와 비호환이라는 문제가 있었다.
SYSCALL/SYSRET — 현대 표준 (64비트)
AMD가 설계하고 Intel이 64비트 모드에서 채택한 명령어 쌍으로, 현재 x86-64 리눅스의 표준 진입 경로다. IDT를 거치지 않고 LSTAR MSR에서 커널 진입점을 직접 로드하며, 스택 전환도 하드웨어가 자동으로 수행하지 않아 최소한의 하드웨어 동작만 발생한다.10
리눅스는 부팅 시 CPU가 어떤 명령어를 지원하는지 확인하고, vDSO(virtual Dynamic Shared Object)11를 통해 해당 시스템에 가장 빠른 진입 경로를 자동으로 선택한다. 따라서 프로그래머는 C 라이브러리 함수만 호출하면 되고, 어떤 명령어가 사용되는지 직접 신경 쓸 필요가 없다.
시스템 호출의 비용
시스템 호출은 일반 함수 호출과 달리 사용자-커널 모드 전환을 수반하므로 비용이 크다. 이 비용은 직접 비용과 간접 비용으로 나눌 수 있다.
- 직접 비용은 모드 전환 자체에서 발생한다.
SYSCALL명령어 실행, 레지스터 저장/복원, 시스템 호출 테이블 디스패치,SYSRET복귀까지 약 100~300ns가 소요된다. Spectre 완화를 위한 간접 분기 제한retpoline12이나 KPTI(Kernel Page Table Isolation)가 활성화되면 추가 비용이 발생한다. - 간접 비용은 모드 전환 이후의 캐시 오염에서 비롯된다. 커널 코드가 실행되면서 사용자 프로그램의 데이터가 L1/L2 캐시에서 밀려나고, 분기 예측기의 히스토리가 교란되어 복귀 후 일시적으로 성능이 저하된다. 컨텍스트 스위치의 간접 비용과 동일한 메커니즘이다.
이러한 비용 때문에 고성능 시스템에서는 시스템 호출 빈도를 줄이는 것이 중요한 최적화 전략이다. 버퍼링을 통해 여러 번의 write()를 하나로 합치거나, io_uring13처럼 배치 처리가 가능한 인터페이스를 사용하는 것이 대표적인 접근법이다.
시스템 호출 추적: strace
시스템 호출의 동작을 직접 관찰하고 싶다면 strace14 유틸리티가 가장 간편한 도구다.
$ strace -c ls /tmp위 명령어는 ls /tmp이 실행되는 동안 발생한 모든 시스템 호출을 집계하여 요약 통계를 출력한다. 특정 시스템 호출만 필터링하고 싶다면 -e trace= 옵션을 사용한다.
$ strace -e trace=write echo "hello"
write(1, "hello\n", 6) = 6
+++ exited with 0 +++echo "hello"가 문자열을 출력하기 위해 write() 시스템 호출을 사용하고, 파일 서술자 1(표준 출력)에 6바이트를 성공적으로 썼음을 확인할 수 있다. strace는 프로그램의 커널과의 상호작용을 투명하게 보여주므로, 디버깅과 성능 분석에 매우 유용하다.
x86-64 vs AArch64
| 항목 | x86-64 | AArch64 |
|---|---|---|
| 시스템 호출 명령어 | SYSCALL | SVC #0 |
| 번호 전달 레지스터 | RAX | X8 |
| 인자 레지스터 | RDI, RSI, RDX, R10, R8, R9 | X0~X5 |
| 반환값 레지스터 | RAX | X0 |
| 하드웨어 자동 저장 | RIP → RCX, RFLAGS → R11 | PC → ELR_EL1, PSTATE → SPSR_EL1 |
| 스택 전환 | 소프트웨어가 수동으로 | SP_EL1으로 자동 전환 |
| 디스패치 테이블 | sys_call_table[] | sys_call_table[] (동일 구조) |
| 복귀 명령어 | SYSRET / IRET | ERET |
| 레거시 경로 | INT 0x80, SYSENTER | 없음 (SVC가 유일) |
AArch64의 SVC는 일반적인 동기 예외와 동일한 경로를 따르므로 구조가 단순하다. 반면 x86-64의 SYSCALL은 속도를 위해 인터럽트 메커니즘을 완전히 우회하는 별도의 빠른 경로를 제공하지만, 스택 전환을 소프트웨어가 직접 처리해야 하는 복잡성이 따른다.
출처
- Silberschatz, A., Galvin, P.B. and Gagne, G. (2018) Operating System Concepts. 10th edn. Hoboken: Wiley.
- Arpaci-Dusseau, R.H. and Arpaci-Dusseau, A.C. (2023) Operating Systems: Three Easy Pieces. 1.10 edn. Arpaci-Dusseau Books.
- Bryant, R.E. and O'Hallaron, D.R. (2016) Computer Systems: A Programmer's Perspective. 3rd edn. Boston: Pearson.
- Love, R. (2010) Linux Kernel Development. 3rd edn. Upper Saddle River: Addison-Wesley.
- Bovet, D.P. and Cesati, M. (2005) Understanding the Linux Kernel. 3rd edn. Sebastopol: O'Reilly.
- Intel Corporation. Intel® 64 and IA-32 Architectures Software Developer's Manual.
- AMD. AMD64 Architecture Programmer's Manual — System Programming.
- Linux kernel source v6.19 —
arch/x86/entry/entry_64.S,arch/x86/entry/syscalls/syscall_64.tbl,arch/arm64/kernel/syscall.c.
*[AMD]: Advanced Micro Devices *[CPU]: Central Processing Unit *[IDT]: Interrupt Descriptor Table *[MSR]: Model-Specific Register
Footnotes
-
이중 모드란 CPU가 최소 두 가지 실행 모드를 제공하여 운영체제 코드와 사용자 코드를 격리하는 하드웨어 메커니즘이다. x86-64에서는 Ring 0(커널)
Ring 3(사용자)의 네 단계를 제공하지만 실질적으로 0과 3만 사용하고, AArch64에서는EL0(사용자)EL3(보안 모니터)의 네 단계를 제공한다. ↩ -
특권 명령어란 커널 모드에서만 실행 가능한 CPU 명령어를 말한다. I/O 장치 접근, 인터럽트 제어, 페이지 테이블 변경 등이 이에 해당한다. 사용자 모드에서 특권 명령어를 실행하려 하면 CPU가 예외exception를 발생시켜 커널에 제어를 넘긴다. ↩
-
IDT(Interrupt Descriptor Table)는 x86에서 인터럽트, 예외, 시스템 호출 각각에 대한 핸들러 함수의 주소를 저장하는 테이블이다. 256개의 엔트리를 가지며,
IDTR레지스터가 이 테이블의 위치를 가리킨다. 커널은 부팅 시 IDT를 초기화하여 각 벡터 번호에 적절한 핸들러를 등록한다. ↩ -
일반 함수 호출의 System V ABI에서는 세 번째 인자를
RDX에, 네 번째 인자를RCX에 넣지만, 시스템 호출에서는 네 번째 인자를R10에 넣는다. 이는SYSCALL명령어가RCX에 복귀 주소를 자동으로 저장하기 때문이다. ↩ -
MSR(Model-Specific Register)은 프로세서 모델에 따라 다른 특수 레지스터로,
RDMSR/WRMSR명령어로 접근한다.LSTAR(MSR 주소0xC0000082)는SYSCALL명령어 실행 시 분기할 커널 진입점 주소를 저장한다. ↩ -
Per-CPU 자료구조는 각 CPU 코어마다 독립된 복사본을 두는 데이터로, 잠금 없이 접근할 수 있어 성능이 좋다. ↩
-
SYSCALL명령어는 인터럽트와 달리 커널 스택으로의 전환을 하드웨어가 자동으로 수행하지 않는다. 따라서 커널 진입 코드가GSBaseMSR을 통해 현재 CPU의struct tss_struct에 접근하여 커널 스택 포인터를 직접 로드한다. 이 구간에서 스택이 아직 사용자 스택인 상태로 커널 코드가 실행되므로, 인터럽트를 비활성화(CLI)한 상태에서 신속하게 처리해야 한다. ↩ -
리눅스 v6.19 기준 x86-64의 시스템 호출 번호는 약 460개에 달한다. 시스템 호출 번호 목록은
arch/x86/entry/syscalls/syscall_64.tbl파일 또는ausyscall --dump명령어로 확인할 수 있다. ↩ -
POSIX(Portable Operating System Interface)는 운영체제 간의 이식성을 보장하기 위해 IEEE가 제정한 표준(IEEE Std 1003.1)으로, 시스템 호출 인터페이스, 셸 명령어, 유틸리티 등을 규정한다. 리눅스, macOS, FreeBSD 등 대부분의 유닉스 계열 운영체제가 이 표준을 따른다. ↩
-
SYSCALL은 약 2025 사이클,200 사이클이 소요된다. 이 차이는 시스템 호출 빈도가 높은 워크로드에서 체감할 수 있을 정도다. ↩INT 0x80은 약 100 -
vDSO(virtual Dynamic Shared Object)는 커널이 사용자 프로세스의 주소 공간에 자동으로 매핑하는 작은 공유 라이브러리다.
clock_gettime()같은 일부 시스템 호출은 커널 모드 전환 없이 vDSO 내부에서 직접 처리될 수 있어 오버헤드가 거의 없다. ↩ -
Retpoline은 Spectre v2(Branch Target Injection) 공격을 완화하기 위해 간접 분기를 반환 명령어(
RET)로 대체하는 기법이다. 시스템 호출 테이블 디스패치 등에서 간접 분기가 사용되므로, retpoline 활성화 시 시스템 호출 비용이 증가한다. ↩ -
io_uring은 리눅스 v5.1에서 도입된 비동기 I/O 인터페이스로, 커널과 사용자 공간이 공유하는 링 버퍼를 통해 시스템 호출 없이 I/O 요청을 제출하고 완료를 수집할 수 있다. 대량의 I/O 연산에서 시스템 호출 오버헤드를 획기적으로 줄인다. ↩ -
strace는 리눅스의ptrace()시스템 호출을 기반으로 동작하는 시스템 호출 추적 도구다. 대상 프로세스가 시스템 호출을 실행할 때마다 커널이 추적 프로세스에 통지하여, 호출 번호, 인자, 반환값을 기록할 수 있다. ↩