fork()는 Unix/Linux 시스템에서 프로세스를 생성하는 핵심 시스템 호출입니다. 이 호출은 한 번 호출되지만 두 프로세스에서 모두 반환되는 독특한 특성을 가지고 있습니다. 이 글에서는 fork()의 동작 원리, 커널 수준의 구현, 그리고 Copy-on-Write 최적화를 살펴봅니다. 프로세스와 시스템 호출에 대한 기본 이해가 도움이 될 것입니다.
fork() 시스템 호출
fork()를 호출하면 현재 프로세스에서 파생된 새로운 프로세스가 생긴다. 함수는 일반적으로 한 번 호출하면 한 번 반환되지만, fork()는 새로운 프로세스를 만들기 때문에 이후 코드는 각 프로세스에서 독립적으로 실행된다. 따라서 fork()는 한 번 호출하고 두 번 반환된다고 표현한다.1
#include <unistd.h>
pid_t fork(void);반환되는 값의 타입은 pid_t이며, 이를 이해하려면 Unix/Linux 시스템이 여러 프로세스를 관리하는 방식을 알아야 한다.
프로세스 ID와 프로세스 그룹 ID
Unix 운영체제는 생성된 각 프로세스에 고유한 번호 프로세스 식별 번호Process Identification Number, PID를 부여하여 관리한다. fork() 시스템 호출로 프로세스를 생성할 때, 실행 중인 현재 프로세스를 부모 프로세스Parent Process라 하고, 새로 생성되는 프로세스를 자식 프로세스Child Process라 한다. 부모-자식 관계로 인해 프로세스의 계층은 트리 구조를 이룬다.
Unix 기반 시스템의 모든 프로세스는 PID 1인 init 프로세스를 최상단 조상으로 하는 계층 구조를 형성한다. 시스템의 모든 프로세스는 정확히 하나의 부모 프로세스를 가지며, 하나 이상의 자식 프로세스를 가질 수 있다. 같은 부모를 가지는 자식 프로세스들을 형제 프로세스Sibling Process라 부른다.
ProcessGroup.png|Bryant and O'Hallaron, 2016, p. 796
프로세스 수가 증가하면 이들을 그룹으로 분류하는데, 이때 사용하는 것이 프로세스 그룹 IDProcess Group ID, PGID다. 같은 PGID를 가진 프로세스들은 한 그룹을 이루며, PID와 PGID가 같은 프로세스를 루트로 하는 서브트리를 구성한다.
새로운 프로세스가 생성되면 부모와 자식 프로세스 간의 관계는 다음 관점에서 규정된다:
- 자원 공유Resource Sharing Option: 부모와 자식 프로세스가 모든 자원을 공유하거나, 일부 자원만 공유하거나, 자원을 공유하지 않을 수 있다.
- 실행Execution Option: 부모와 자식이 동시에 실행되거나, 자식이 종료될 때까지 부모가 기다릴 수 있다.
- 주소 공간Address Space Option: 자식이 부모와 동일한 데이터를 가지거나 새로운 데이터를 가질 수 있다.
fork()의 반환값
fork()는 pid_t 타입의 값을 반환한다. 한 번의 호출이 두 프로세스에서 반환되기 때문에, 부모 프로세스에서는 자식 프로세스의 PID를 받고, 자식 프로세스에서는 0을 받는다. 오류 발생 시에는 음수가 반환된다.1
struct task_struct {
// ...
/*
* Pointers to the (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->real_parent->pid)
*/
/* Real parent process: */
struct task_struct __rcu *real_parent;
/* Recipient of SIGCHLD, wait4() reports: */
struct task_struct __rcu *parent;
/*
* Children/sibling form the list of natural children:
*/
struct list_head children;
struct list_head sibling;
struct task_struct *group_leader;
// ...리눅스 커널에서 관리하는 각 프로세스의 task_struct 구조체에는 부모, 자식, 형제 프로세스를 가리키는 멤버들이 있다. parent와 real_parent 멤버는 부모 프로세스를 가리키고, children은 자식 프로세스 리스트를, sibling은 형제 프로세스를 가리킨다. group_leader 멤버는 프로세스 그룹의 최상위 프로세스를 참조한다. 이 계층 구조 덕분에 시스템의 어떤 프로세스에서도 다른 특정 프로세스를 찾아갈 수 있다. Process Control Block에서 task_struct에 대해 더 자세히 알아볼 수 있다.
fork()의 구현
fork()의 인터페이스는 간단하지만, 커널 수준의 구현은 복잡하다. 사용자 프로그램이 fork()를 호출하면 GNU C 라이브러리(glibc)가 이를 받아 내부적으로 clone() 시스템 호출을 수행한다.2 커널에 진입하면 sys_fork() → kernel_clone() 경로를 따른다. 한편 clone3()는 clone()의 확장 버전으로, 사용자 공간에서 struct clone_args를 통해 더 정밀한 제어를 할 수 있다. clone3() 경로는 sys_clone3() → kernel_clone()으로 이어지며, 결국 두 경로 모두 kernel_clone()에서 합류한다.
kernel_clone()
그래서 실제 프로세스 생성의 핵심은 kernel_clone()에서 이루어진다:
/*
* Ok, this is the main fork-routine.
*
* It copies the process, and if successful kick-starts
* it and waits for it to finish using the VM if required.
*
* args->exit_signal is expected to be checked for sanity by the caller.
*/
pid_t kernel_clone(struct kernel_clone_args *args)
{
u64 clone_flags = args->flags;
struct completion vfork;
struct pid *pid;
struct task_struct *p;
int trace = 0;
pid_t nr;
/*
* For legacy clone() calls, CLONE_PIDFD uses the parent_tid argument
* to return the pidfd. Hence, CLONE_PIDFD and CLONE_PARENT_SETTID are
* mutually exclusive. With clone3() CLONE_PIDFD has grown a separate
* field in struct clone_args and it still doesn't make sense to have
* them both point at the same memory location. Performing this check
* here has the advantage that we don't need to have a separate helper
* to check for legacy clone().
*/
if ((clone_flags & CLONE_PIDFD) &&
(clone_flags & CLONE_PARENT_SETTID) &&
(args->pidfd == args->parent_tid))
return -EINVAL;
/*
* Determine whether and which event to report to ptracer. When
* called from kernel_thread or CLONE_UNTRACED is explicitly
* requested, no event is reported; otherwise, report if the event
* for the type of forking is enabled.
*/
if (!(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if (args->exit_signal != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
p = copy_process(NULL, trace, NUMA_NO_NODE, args);
add_latent_entropy();
if (IS_ERR(p))
return PTR_ERR(p);
/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/
trace_sched_process_fork(current, p);
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, args->parent_tid);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
if (IS_ENABLED(CONFIG_LRU_GEN_WALKS_MMU) && !(clone_flags & CLONE_VM)) {
/* lock the task to synchronize with memcg migration */
task_lock(p);
lru_gen_add_mm(p->mm);
task_unlock(p);
}
wake_up_new_task(p);
/* forking complete and child started to run, tell ptracer */
if (unlikely(trace))
ptrace_event_pid(trace, pid);
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
return nr;
}kernel_clone()의 핵심은 copy_process() 함수를 호출하는 것이다. 이 함수가 성공하면, 새로운 자식 프로세스를 깨워(wake_up_new_task()) 실행을 시작한다.
copy_process() 함수
copy_process() 함수는 실제 프로세스 복사 작업을 수행한다. v7.0 기준으로 약 560줄에 달하는 대형 함수이며, 복잡한 구현을 핵심 단계로 요약하면 다음과 같다.
- clone 플래그 검증: 상호 배타적이거나 논리적으로 성립할 수 없는 플래그 조합을 걸러낸다. 예를 들어
CLONE_THREAD는 반드시CLONE_SIGHAND를 동반해야 하고,CLONE_SIGHAND는CLONE_VM을 전제한다. - 커널 스택 및 프로세스 구조체 복제:
dup_task_struct()함수를 호출해 새로운 커널 스택,thread_info,task_struct를 만든다. 이 시점에서 부모와 자식의 프로세스 서술자는 동일하다. - 자격 증명 복사 및 자원 제한 확인:
copy_creds()로 자격 증명을 복사하고,RLIMIT_NPROC을 초과하지 않는지 검증한다. - 플래그 정리 및 초기화:
PF_SUPERPRIV플래그를 초기화하고PF_FORKNOEXEC를 설정한다. 통계 정보, 타이머, I/O 카운터 등 부모로부터 물려받지 않아야 할 항목들을 정리한다. - 스케줄러 설정:
sched_fork()로 스케줄링 관련 초기화를 수행하고 CPU를 배정한다. - 자원 복제 또는 공유:
clone()함수에 전달된 플래그 값에 따라 파일 서술자, 파일시스템 정보, 시그널 핸들러, 주소 공간, 네임스페이스 등을 복제하거나 공유한다. 스레드는 보통 이 자원들을 공유하며, 별도의 프로세스는 개별적으로 복제한다. - 새 PID 할당:
alloc_pid()함수를 호출해 자식 프로세스에 새로운 PID를 할당한다. - 스레드 그룹 및 부모-자식 관계 설정:
CLONE_THREAD여부에 따라 그룹 리더와 TGID를 설정하고,tasklist_lock을 잡은 뒤 프로세스 리스트에 등록한다. - 사후 처리:
proc_fork_connector(),cgroup_post_fork(),perf_event_fork()등으로 서브시스템에 새 프로세스의 탄생을 알린다.
다음은 copy_process() 함수의 실제 소스 코드에서 핵심 로직을 발췌한 것이다. #ifdef 블록과 반복적인 에러 처리 경로는 가독성을 위해 생략했으며, 전체 코드는 kernel/fork.c에서 확인할 수 있다.
__latent_entropy struct task_struct *copy_process(
struct pid *pid,
int trace,
int node,
struct kernel_clone_args *args)
{
int pidfd = -1, retval;
struct task_struct *p;
struct multiprocess_signals delayed;
struct file *pidfile = NULL;
const u64 clone_flags = args->flags;
struct nsproxy *nsp = current->nsproxy;
/*
* Thread groups must share signals as well, and detached threads
* can only be started up within the thread group.
*/
if ((clone_flags & CLONE_THREAD) && !(clone_flags & CLONE_SIGHAND))
return ERR_PTR(-EINVAL);
/*
* Shared signal handlers imply shared VM. By way of the above,
* thread groups also imply shared VM. Blocking this case allows
* for various simplifications in other code.
*/
if ((clone_flags & CLONE_SIGHAND) && !(clone_flags & CLONE_VM))
return ERR_PTR(-EINVAL);
/* ... additional flag validations (CLONE_PARENT, CLONE_PIDFD,
CLONE_AUTOREAP, CLONE_NNP, CLONE_PIDFD_AUTOKILL, etc.) ... */
retval = -ENOMEM;
p = dup_task_struct(current, node);
if (!p)
goto fork_out;
p->flags &= ~PF_KTHREAD;
if (args->kthread)
p->flags |= PF_KTHREAD;
if (args->user_worker)
p->flags |= PF_USER_WORKER;
if (args->io_thread)
p->flags |= PF_IO_WORKER;
retval = copy_creds(p, clone_flags);
if (retval < 0)
goto bad_fork_free;
retval = -EAGAIN;
if (is_rlimit_overlimit(task_ucounts(p), UCOUNT_RLIMIT_NPROC,
rlimit(RLIMIT_NPROC))) {
if (p->real_cred->user != INIT_USER &&
!capable(CAP_SYS_RESOURCE) && !capable(CAP_SYS_ADMIN))
goto bad_fork_cleanup_count;
}
p->flags &= ~(PF_SUPERPRIV | PF_WQ_WORKER | PF_IDLE | PF_NO_SETAFFINITY);
p->flags |= PF_FORKNOEXEC;
INIT_LIST_HEAD(&p->children);
INIT_LIST_HEAD(&p->sibling);
p->utime = p->stime = p->gtime = 0;
/* Perform scheduler related setup. Assign this task to a CPU. */
retval = sched_fork(clone_flags, p);
if (retval)
goto bad_fork_cleanup_policy;
retval = audit_alloc(p);
retval = security_task_alloc(p, clone_flags);
/* copy all the process information */
retval = copy_semundo(clone_flags, p);
retval = copy_files(clone_flags, p, args->no_files);
retval = copy_fs(clone_flags, p);
retval = copy_sighand(clone_flags, p);
retval = copy_signal(clone_flags, p);
retval = copy_mm(clone_flags, p);
retval = copy_namespaces(clone_flags, p);
retval = copy_io(clone_flags, p);
retval = copy_thread(p, args);
if (pid != &init_struct_pid) {
pid = alloc_pid(p->nsproxy->pid_ns_for_children,
args->set_tid, args->set_tid_size);
if (IS_ERR(pid))
goto bad_fork_cleanup_thread;
}
if (clone_flags & CLONE_PIDFD) {
unsigned flags = PIDFD_STALE;
if (clone_flags & CLONE_THREAD)
flags |= PIDFD_THREAD;
if (clone_flags & CLONE_PIDFD_AUTOKILL)
flags |= PIDFD_AUTOKILL;
retval = pidfd_prepare(pid, flags, &pidfile);
if (retval < 0)
goto bad_fork_free_pid;
pidfd = retval;
retval = put_user(pidfd, args->pidfd);
if (retval)
goto bad_fork_put_pidfd;
}
/* ok, now we should be set up.. */
p->pid = pid_nr(pid);
if (clone_flags & CLONE_THREAD) {
p->group_leader = current->group_leader;
p->tgid = current->tgid;
} else {
p->group_leader = p;
p->tgid = p->pid;
}
p->start_time = ktime_get_ns();
p->start_boottime = ktime_get_boottime_ns();
/*
* Make it visible to the rest of the system, but dont wake it up yet.
* Need tasklist lock for parent etc handling!
*/
write_lock_irq(&tasklist_lock);
/* CLONE_PARENT re-uses the old parent */
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) {
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
if (clone_flags & CLONE_THREAD)
p->exit_signal = -1;
else
p->exit_signal = current->group_leader->exit_signal;
} else {
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
p->exit_signal = args->exit_signal;
}
spin_lock(¤t->sighand->siglock);
/* No more failure paths after this point. */
copy_seccomp(p);
init_task_pid_links(p);
if (likely(p->pid)) {
ptrace_init_task(p, (clone_flags & CLONE_PTRACE) || trace);
init_task_pid(p, PIDTYPE_PID, pid);
if (thread_group_leader(p)) {
init_task_pid(p, PIDTYPE_TGID, pid);
init_task_pid(p, PIDTYPE_PGID, task_pgrp(current));
init_task_pid(p, PIDTYPE_SID, task_session(current));
p->signal->has_child_subreaper =
p->real_parent->signal->has_child_subreaper ||
p->real_parent->signal->is_child_subreaper;
list_add_tail(&p->sibling, &p->real_parent->children);
list_add_tail_rcu(&p->tasks, &init_task.tasks);
attach_pid(p, PIDTYPE_TGID);
attach_pid(p, PIDTYPE_PGID);
attach_pid(p, PIDTYPE_SID);
__this_cpu_inc(process_counts);
} else {
current->signal->nr_threads++;
current->signal->quick_threads++;
atomic_inc(¤t->signal->live);
refcount_inc(¤t->signal->sigcnt);
task_join_group_stop(p);
list_add_tail_rcu(&p->thread_node,
&p->signal->thread_head);
}
attach_pid(p, PIDTYPE_PID);
nr_threads++;
}
total_forks++;
spin_unlock(¤t->sighand->siglock);
write_unlock_irq(&tasklist_lock);
if (pidfile)
fd_install(pidfd, pidfile);
proc_fork_connector(p);
sched_post_fork(p);
cgroup_post_fork(p, args);
perf_event_fork(p);
trace_task_newtask(p, clone_flags);
uprobe_copy_process(p, clone_flags);
user_events_fork(p, clone_flags);
copy_oom_score_adj(clone_flags, p);
return p;
/* Error cleanup paths - unwind everything in reverse order */
bad_fork_put_pidfd:
if (clone_flags & CLONE_PIDFD) {
fput(pidfile);
put_unused_fd(pidfd);
}
bad_fork_free_pid:
if (pid != &init_struct_pid)
free_pid(pid);
bad_fork_cleanup_thread:
exit_thread(p);
/* ... further cleanup: IO, namespaces, mm, signal, sighand,
fs, files, semundo, security, audit, perf, sched, creds ... */
bad_fork_free:
put_task_stack(p);
delayed_free_task(p);
fork_out:
return ERR_PTR(retval);
}Copy-on-Write
오늘날 fork()는 부모 프로세스의 모든 자원을 자식 프로세스로 복사하지 않는다. 이는 공유 가능한 데이터를 최대한 복사하지 않으면서도 독립적인 프로세스를 제공하기 위한 것이다. 이때 핵심 개념이 Copy-on-Write3다.
Copy-on-Write는 기록 시 복사를 의미하며, 프로세스의 주소 공간에 실제 쓰기 작업이 일어날 때까지 데이터 복사를 지연하는 최적화 기법이다. 프로세스는 각자의 가상 메모리를 가지면서도 물리 메모리를 공유한다. Copy-on-Write로 지정된 데이터에 쓰기 작업이 발생하면, 그 시점에서만 필요한 메모리 페이지를 복사하고 기록한다.
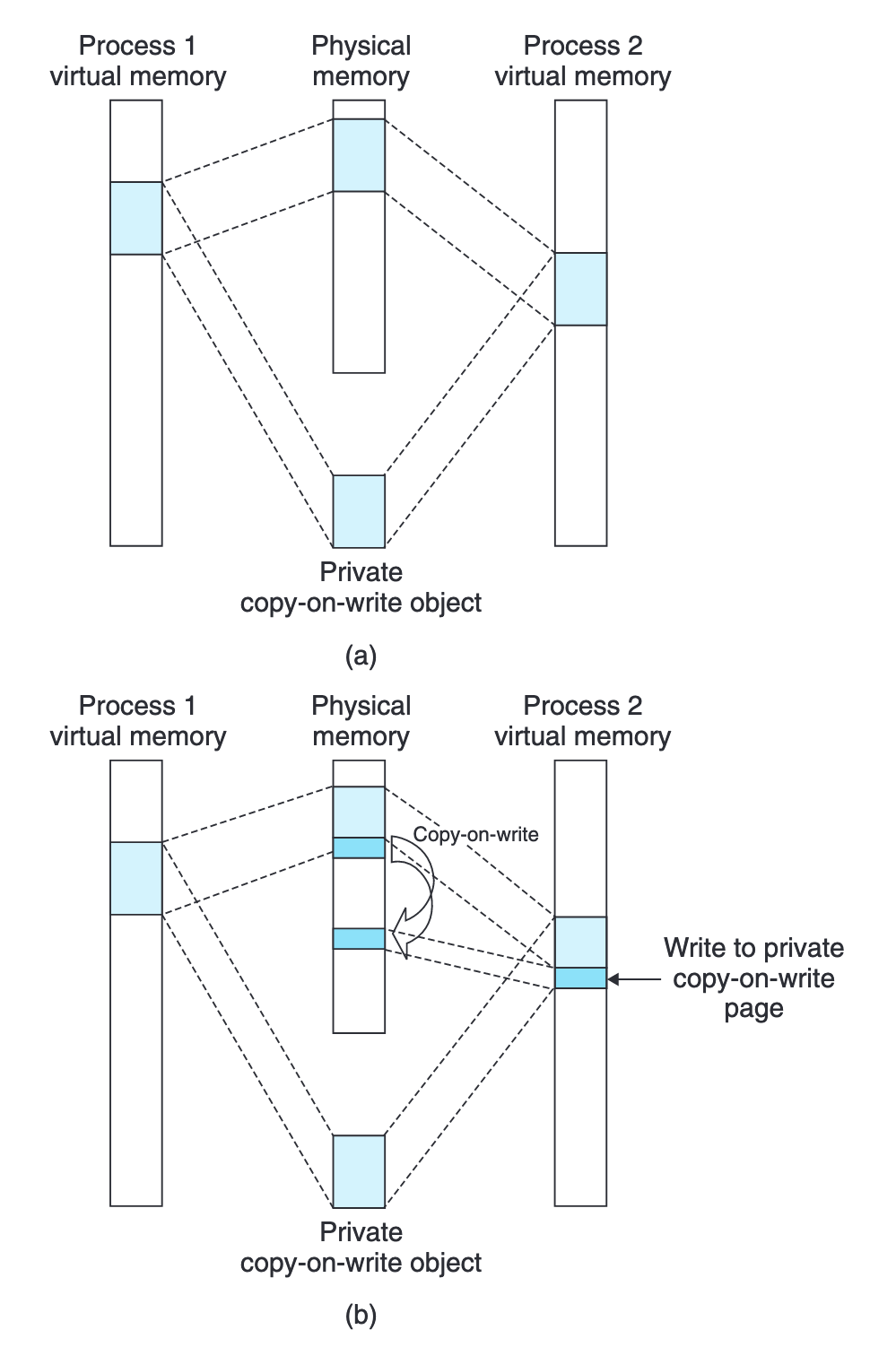
과거 Linux 커널(v2.6.32 이전)은 의도적으로 자식 프로세스를 먼저 실행했다. 부모 프로세스가 먼저 실행되어 주소 공간에 쓰기 작업이 발생할 경우, 불필요한 Copy-on-Write가 일어나는 것을 방지하기 위함이었다. 이후 CFS 스케줄러에서는 sysctl_sched_child_runs_first 파라미터로 이 동작을 제어할 수 있었으나, v6.6부터 기본 스케줄러가 EEVDF로 전환되면서 이 파라미터는 완전히 제거되었다.4 EEVDF는 적격 가상 마감 시한eligible virtual deadline에 따라 실행 순서를 결정하므로, 부모와 자식 중 누가 먼저 실행되는지는 스케줄러의 일반적인 판단에 맡겨진다. 실질적으로는 fork()를 호출한 부모 프로세스가 이미 CPU에서 실행 중이므로 대부분 부모가 먼저 이어서 실행된다.
특히 fork() 직후 즉시 exec()을 호출하는 패턴에서는 자식 프로세스의 주소 공간이 완전히 교체되므로 Copy-on-Write로 인한 페이지 복사가 발생하지 않는다. 결국 fork()가 실제로 하는 일은 부모 프로세스의 페이지 테이블을 복사하고 자식 프로세스를 위한 프로세스 서술자를 만드는 것뿐이다. exec()에서 프로세스의 주소 공간을 완전히 교체하는 방식을 자세히 알아볼 수 있다.
출처
- Silberschatz, A., Galvin, P. B. and Gagne, G. (2018) Operating System Concepts. 10th edn. Hoboken: John Wiley & Sons.
- Bryant, R. E. and O'Hallaron, D. R. (2016) Computer Systems: A Programmer's Perspective. 3rd edn. Boston: Pearson.
- Kerrisk, M. (2018) The Linux Programming Interface. 9th printing. San Francisco: No Starch Press.
- Amini, K. (2019) Extreme C: Taking you to the limit in Concurrency, OOP, and the most advanced capabilities of C. 1st edn. Birmingham: Packt Publishing.
- Love, R. (2010) Linux Kernel Development. 3rd edn. Upper Saddle River: Addison-Wesley Professional.
- Linux kernel source code v7.0:
kernel/fork.c,kernel/sched/fair.c
*[EEVDF]: Earliest Eligible Virtual Deadline First *[PGID]: Process Group ID *[PID]: Process Identifier
Footnotes
-
이를 통해 부모와 자식 프로세스는 반환값으로 자신이 어떤 프로세스인지를 구분할 수 있다. 부모 프로세스는 반환값이 양수(자식의 PID)이고, 자식 프로세스는 0이다. ↩ ↩2
-
glibc 2.3.3부터
fork()래퍼는 커널의fork()시스템 호출 대신clone(SIGCHLD)시스템 호출을 사용한다. glibc는clone3()의 래퍼를 제공하지 않으며,clone3()를 사용하려면syscall(2)을 직접 호출해야 한다. fork(2) - Linux manual page 참고. ↩ -
Copy-on-Write는 자원 복사를 실제 수정 시점까지 지연하는 최적화 전략이다. 자식 프로세스가 부모의 페이지 테이블을 공유하다가, 쓰기 작업이 발생하는 시점에 해당 페이지만 복사한다. ↩
-
CFS 스케줄러(Linux 2.6.23~6.5)에서는
/proc/sys/kernel/sched_child_runs_first파라미터로 자식 우선 실행을 제어할 수 있었다.task_fork_fair()함수에서 이 값이 설정되어 있으면 자식의vruntime을 부모보다 작게 조정했다. EEVDF 스케줄러(Linux 6.6+)로 전환되면서 이 파라미터와 관련 로직이 완전히 제거되었다. ↩