하나의 물리 서버 위에 여러 운영체제를 동시에 돌릴 수 있다면 어떨까요? 가상머신Virtual Machine은 하드웨어를 소프트웨어로 흉내 내어, 하나의 물리 컴퓨터 위에서 여러 개의 독립된 컴퓨터가 동작하는 것처럼 만드는 기술입니다. 이 글에서는 가상머신이 무엇이고, 왜 필요하며, 어떤 원리로 작동하는지를 살펴봅니다.
가상머신이란 무엇인가
가상머신Virtual Machine, VM이란 소프트웨어로 구현된 컴퓨터다. 물리적인 컴퓨터(CPU, 메모리, 디스크, 네트워크 카드 등)가 하는 일을 소프트웨어가 그대로 흉내 내어, 그 위에서 운영체제와 애플리케이션이 "진짜 컴퓨터 위에서 실행되고 있다"고 착각하게 만드는 것이다.
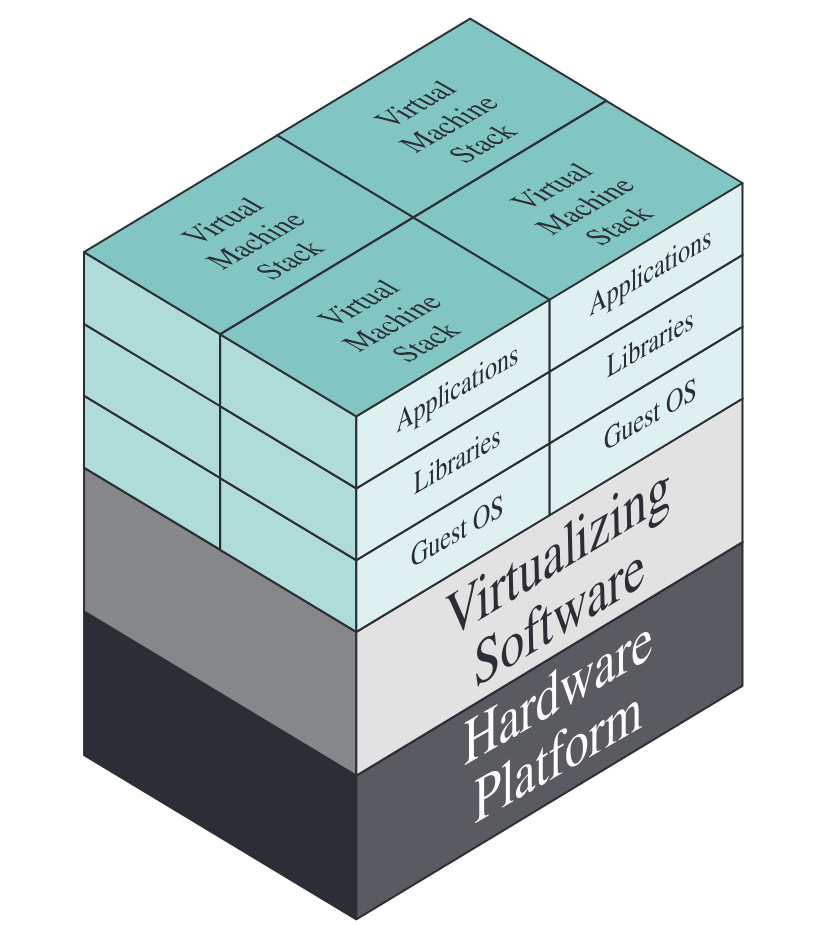
여기서 주의할 점이 하나 있다. 메모리 가상화에서 다룬 가상화Virtualization는 물리 메모리를 프로세스마다 독립된 주소 공간으로 추상화하는 기법이었다. 이번 글에서 다루는 가상머신은 메모리뿐 아니라 CPU, 디스크, 네트워크를 포함한 컴퓨터 전체를 추상화하는 것이므로, 추상화의 단위와 범위가 완전히 다르다.


왜 가상머신이 필요한가
가상머신이 해결하는 문제를 이해하면, 이 기술이 왜 탄생했는지가 명확해진다.
서버 통합과 자원 효율
과거에는 하나의 물리 서버에 하나의 운영체제, 하나의 애플리케이션을 배치하는 것이 일반적이었다. 웹 서버, 메일 서버, 데이터베이스 서버가 각각 물리 서버 한 대씩을 차지했고, 실제 CPU 사용률은 10~15%에 불과한 경우가 많았다. 가상머신을 사용하면 하나의 물리 서버 위에 여러 VM을 올려 자원 활용률을 끌어올릴 수 있다(Silberschatz, Galvin and Gagne, 2018).
격리와 보안
각 VM은 독립된 운영체제를 실행하므로, 하나의 VM에서 보안 사고가 발생해도 다른 VM에는 영향을 미치지 않는다. 이 격리 수준은 단순히 프로세스 간 격리보다 훨씬 강력하다. 프로세스 격리는 같은 커널을 공유하므로 커널 취약점이 발견되면 모든 프로세스가 위험해지지만, VM 격리는 커널 자체가 별개이므로 한 VM의 커널이 뚫려도 다른 VM의 커널은 무사하다.
호환성과 이식성
서로 다른 운영체제를 동시에 실행할 수 있다. macOS 위에서 Windows를 돌리거나, 하나의 리눅스 서버 위에서 다양한 리눅스 배포판을 동시에 운영하는 것이 가능하다. 또한 VM의 상태를 파일로 저장하여 다른 물리 서버로 옮기는 라이브 마이그레이션live migration1도 가능해서, 물리 서버 교체나 유지보수 시에도 서비스 중단 없이 VM을 이동시킬 수 있다.
CPU 가상화
가상머신의 핵심 도전은 CPU 가상화다. 게스트 OS는 자신이 하드웨어를 직접 제어하고 있다고 생각하지만, 실제로는 하이퍼바이저가 중간에서 이를 가로채야 한다. 이 문제를 이해하기 위해서는 먼저 CPU의 특권 수준privilege level을 알아야 한다.
시스템 호출에서 살펴본 것처럼, CPU는 이중 모드dual mode를 지원하여 커널 모드(Ring 0)와 사용자 모드(Ring 3)를 구분한다. 커널 모드에서만 실행할 수 있는 특권 명령어privileged instruction에는 I/O 장치 제어, 인터럽트 관리, 페이지 테이블 변경 등이 포함된다.
문제는 게스트 OS도 자신의 커널 모드에서 이러한 특권 명령어를 실행하려 한다는 점이다. 그러나 게스트 OS는 실제로는 Ring 0에서 실행되지 않는다. 하이퍼바이저가 Ring 0을 차지하고 있기 때문이다. 그렇다면 게스트 OS의 특권 명령어는 어떻게 처리해야 할까?
Trap-and-Emulate
가장 전통적인 해결책은 트랩 앤 에뮬레이트Trap-and-Emulate다. 게스트 OS를 사용자 모드(Ring 1 또는 Ring 3)에서 실행하고, 게스트 OS가 특권 명령어를 실행하려 하면 CPU가 자동으로 예외(트랩)를 발생시킨다. 이 트랩을 하이퍼바이저가 받아서, 해당 명령어가 의도한 동작을 소프트웨어로 흉내 내는(에뮬레이트하는) 것이다.
이 방식은 1974년 Popek과 Goldberg가 정립한 가상화 정리virtualization theorem2에 기반한다. 이 정리에 따르면 효율적인 가상화가 가능하려면, 모든 민감한 명령어sensitive instruction3가 특권 명령어여야 한다.
x86의 가상화 구멍
문제는 x86 아키텍처가 이 조건을 만족하지 않았다는 점이다. x86에는 민감하지만 특권이 아닌sensitive but not privileged 명령어가 17개 존재했다(Robin and Irvine, 2000). 예를 들어 POPF 명령어는 플래그 레지스터를 변경하는데, Ring 0에서 실행하면 인터럽트 플래그(IF)까지 변경하지만 Ring 3에서 실행하면 IF 변경을 조용히 무시한다. 트랩이 발생하지 않으므로 하이퍼바이저가 이를 가로챌 수 없고, 게스트 OS는 인터럽트를 비활성화했다고 착각하게 된다.
이 구멍을 메우기 위해 두 가지 소프트웨어적 접근이 등장했다.
전가상화: 이진 변환
전가상화full virtualization에서는 하이퍼바이저가 게스트 OS의 코드를 실행 전에 스캔하여, 문제가 되는 명령어를 안전한 코드 조각으로 동적 치환하는 이진 변환binary translation4을 수행한다. 게스트 OS의 수정 없이 가상화가 가능하다는 장점이 있지만, 변환 과정에서 성능 오버헤드가 발생한다. VMware의 초기 제품들이 이 방식을 사용했다.
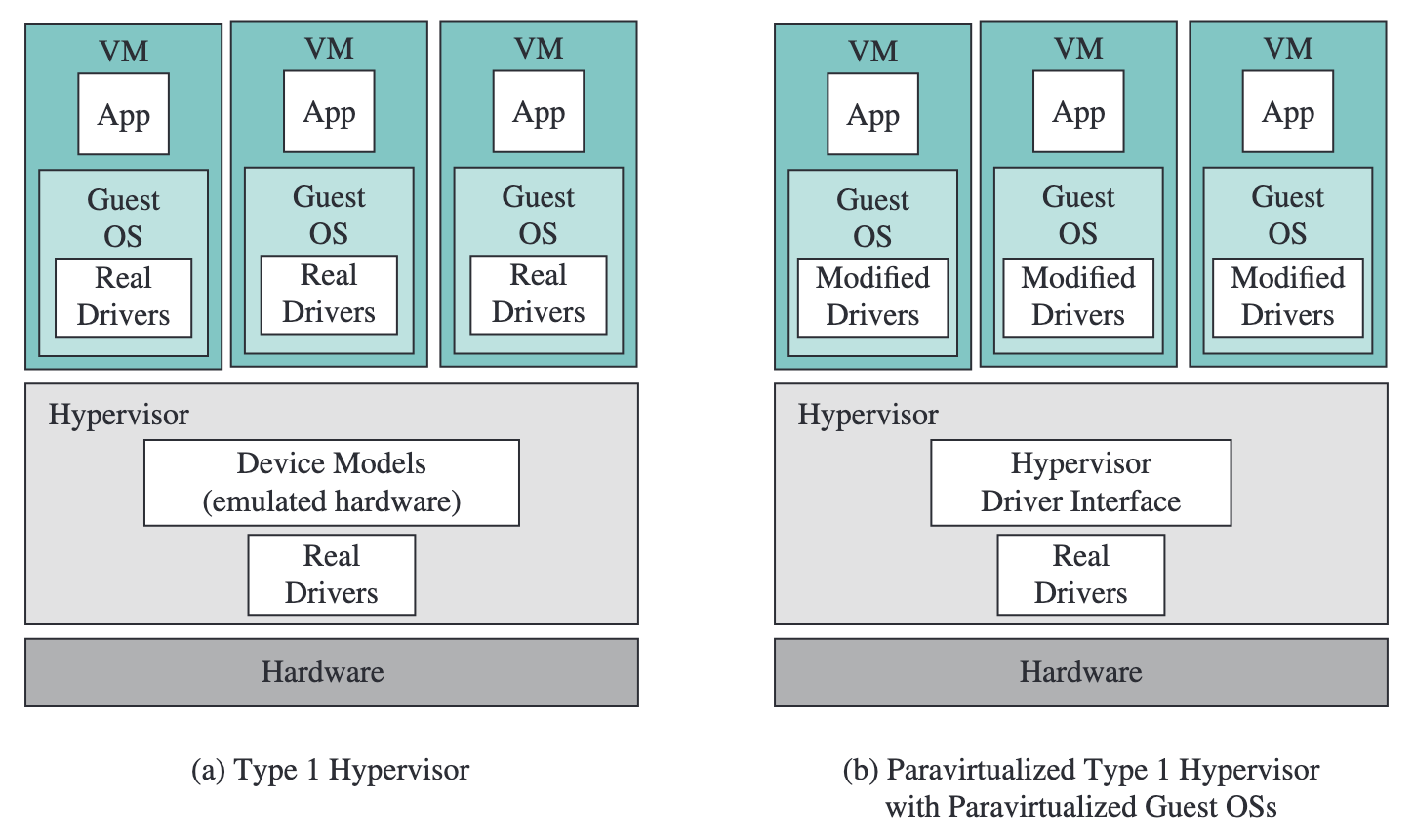
반가상화: 게스트 OS 수정
반가상화para-virtualization5에서는 게스트 OS의 소스 코드를 직접 수정하여, 문제가 되는 명령어를 하이퍼바이저 호출hypercall6로 대체한다. 시스템 호출이 사용자 프로그램이 커널에 서비스를 요청하는 인터페이스인 것처럼, 하이퍼콜은 게스트 OS가 하이퍼바이저에 서비스를 요청하는 인터페이스다.
| 시스템 호출 | 하이퍼콜 | |
|---|---|---|
| 요청자 | 사용자 프로그램 | 게스트 OS |
| 수신자 | 커널 | 하이퍼바이저 |
| 트리거 | SYSCALL / SVC | VMCALL / HVC |
| 목적 | 커널 서비스 요청 | 하이퍼바이저 서비스 요청 |
반가상화는 이진 변환보다 성능이 좋지만, 게스트 OS의 소스 코드를 수정해야 하므로 Windows처럼 소스가 비공개인 OS에는 적용하기 어렵다. Xen이 이 방식의 선구자였다.
하드웨어 지원 가상화
x86의 가상화 구멍을 근본적으로 해결한 것은 하드웨어의 진화였다. 2005~2006년에 Intel은 VT-x7를, AMD는 AMD-V8를 도입하여, CPU에 새로운 실행 모드를 추가했다.
기존에는 Ring 0~3만 존재했지만, 하드웨어 가상화 확장은 그 아래에 루트 모드root mode와 비루트 모드non-root mode라는 새로운 계층을 도입했다. 하이퍼바이저는 루트 모드의 Ring 0에서 실행되고, 게스트 OS는 비루트 모드의 Ring 0에서 실행된다. 게스트 OS가 비루트 모드에서 민감한 명령어를 실행하면, CPU가 자동으로 루트 모드로 전환(VM Exit9)하여 하이퍼바이저에 제어를 넘긴다.


이 전환 과정에서 CPU 상태를 저장하고 복원하는 데 사용되는 자료구조가 VMCS(Virtual Machine Control Structure)10다. VMCS에는 게스트의 레지스터 상태, VM Exit 조건, 하이퍼바이저 진입점 등이 기록되어 있다. 컨텍스트 스위치에서 task_struct가 프로세스의 상태를 저장하는 것처럼, VMCS는 가상머신의 상태를 저장한다.
| 컨텍스트 스위치 | VM Exit/Entry | |
|---|---|---|
| 상태 저장소 | PCB (task_struct) | VMCS/VMCB11 |
| 전환 대상 | 프로세스 ↔ 프로세스 | 게스트 ↔ 하이퍼바이저 |
| 트리거 | 타이머 인터럽트, 블로킹 I/O 등 | 민감한 명령어, 인터럽트 등 |
| 비용 | 약 1~10μs | 약 1~20μs |
| 주소 공간 전환 | CR3 / TTBR0 변경 | EPT/NPT 전환 포함 |
하드웨어 지원 가상화 덕분에 게스트 OS를 수정할 필요도, 이진 변환을 할 필요도 없어졌다. 오늘날 KVM, VMware ESXi, Hyper-V 등 대부분의 하이퍼바이저가 이 방식을 사용한다.
메모리 가상화: 주소 변환의 주소 변환
메모리 가상화에서 살펴본 것처럼, 일반적인 운영체제는 가상 주소Virtual Address, VA를 페이지 테이블을 통해 물리 주소Physical Address, PA로 변환한다. 그런데 가상머신 환경에서는 상황이 한 단계 더 복잡해진다.
게스트 OS는 자신이 관리하는 가상 주소(GVA, Guest Virtual Address)를 자신의 페이지 테이블로 물리 주소(GPA, Guest Physical Address)로 변환한다. 그러나 이 "물리 주소"는 실제 물리 주소가 아니라, 하이퍼바이저가 할당한 가상의 물리 주소다. 실제 하드웨어의 물리 주소(HPA, Host Physical Address)에 접근하려면 한 번 더 변환이 필요하다.
이 이중 변환을 효율적으로 처리하기 위해 하드웨어에 도입된 것이 EPT(Extended Page Table)12와 NPT(Nested Page Table)13이다. EPT는 Intel, NPT는 AMD의 명칭으로, 둘 다 GPA→HPA 변환을 하드웨어가 자동으로 수행하는 2단계 주소 변환two-dimensional page walk을 지원한다. 이 하드웨어 지원이 없으면 하이퍼바이저가 게스트의 페이지 테이블과 실제 페이지 테이블을 동기화하는 섀도우 페이지 테이블shadow page table14을 유지해야 했는데, 이는 구현이 복잡하고 성능 비용이 컸다.
TLB도 가상화의 영향을 받는다. 하드웨어 가상화가 도입되기 전에는 VM 전환 시마다 TLB를 완전히 플러시해야 했다. 오늘날에는 컨텍스트 스위치에서 살펴본 PCID/ASID와 유사한 VPID(Virtual Processor Identifier)15 태그를 TLB 항목에 부여하여, VM 간 전환 시에도 TLB 플러시를 최소화한다.
가상머신 vs 컨테이너
가상머신과 자주 비교되는 기술이 컨테이너(container)다. Docker로 대표되는 컨테이너는 가상머신과 동일한 목표(격리된 실행 환경 제공)를 추구하지만, 격리를 달성하는 방식이 근본적으로 다르다.
가상머신은 하이퍼바이저 위에 완전한 게스트 OS를 올리는 반면, 컨테이너는 호스트 OS의 커널을 공유하면서 네임스페이스(namespace)16와 cgroup17을 통해 프로세스 수준의 격리를 제공한다.
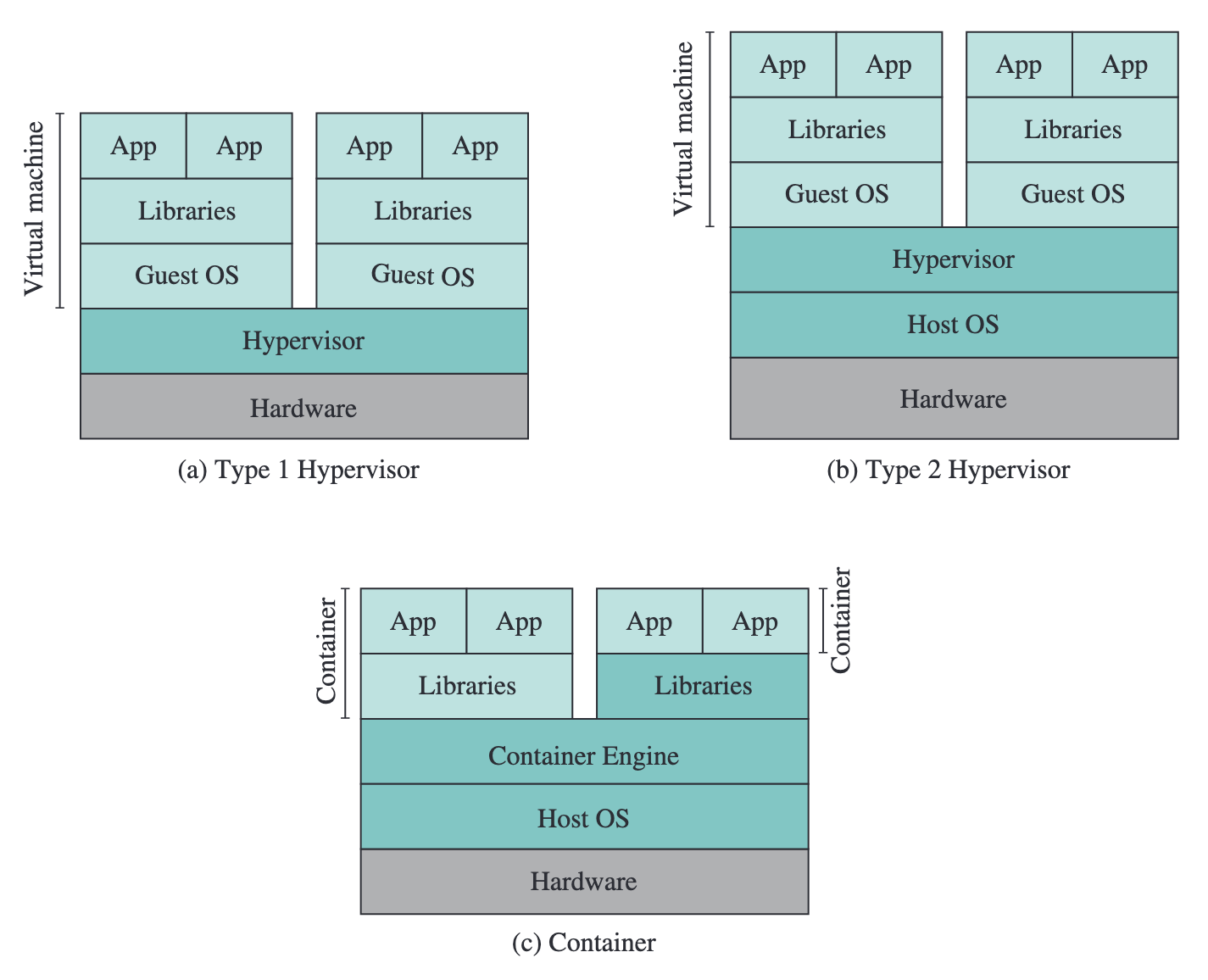


| 항목 | 가상머신 | 컨테이너 |
|---|---|---|
| 격리 단위 | 운영체제 전체 | 프로세스 그룹 |
| 커널 | 게스트마다 별도 | 호스트와 공유 |
| 시작 시간 | 수십 초~수 분 | 수 밀리초~수 초 |
| 이미지 크기 | 수 GB | 수십~수백 MB |
| 성능 오버헤드 | 중간 (VM Exit/Entry) | 거의 없음 (네이티브에 근접) |
| 격리 강도 | 강함 (하드웨어 수준) | 상대적으로 약함 (커널 공유) |
| 대표 기술 | VMware, KVM, Hyper-V | Docker, containerd |
| 주요 용도 | 이종 OS 실행, 강한 격리 | 마이크로서비스, CI/CD |
두 기술은 상호 배타적이지 않다. 클라우드 환경에서는 VM 위에서 컨테이너를 실행하여, VM의 강한 격리와 컨테이너의 경량성을 동시에 취하는 구성이 일반적이다.
출처
- Silberschatz, A., Galvin, P. B., and Gagne, G. (2018) Operating System Concepts. 10th ed. Hoboken, NJ: Wiley.
- Tanenbaum, A. S. and Bos, H. (2023) Modern Operating Systems. 5th ed. London: Pearson.
- Popek, G. J. and Goldberg, R. P. (1974) 'Formal Requirements for Virtualizable Third Generation Architectures', Communications of the ACM, 17(7), pp.412-421.
- Robin, J. S. and Irvine, C. E. (2000) 'Analysis of the Intel Pentium's Ability to Support a Secure Virtual Machine Monitor', Proceedings of the 9th USENIX Security Symposium.
- Adams, K. and Agesen, O. (2006) 'A Comparison of Software and Hardware Techniques for x86 Virtualization', ASPLOS XII.
- Barham, P. et al. (2003) 'Xen and the Art of Virtualization', Proceedings of the 19th ACM Symposium on Operating Systems Principles (SOSP '03).
- Kivity, A. et al. (2007) 'kvm: the Linux Virtual Machine Monitor', Proceedings of the Linux Symposium.
- Clark, C. et al. (2005) 'Live Migration of Virtual Machines', Proceedings of the 2nd USENIX Symposium on Networked Systems Design and Implementation (NSDI '05).
- Waldspurger, C. A. (2002) 'Memory Resource Management in VMware ESX Server', Proceedings of the 5th USENIX Symposium on Operating Systems Design and Implementation (OSDI '02).
- Intel Corporation. Intel® 64 and IA-32 Architectures Software Developer's Manual, Volume 3, Chapters 23-28.
- AMD. AMD64 Architecture Programmer's Manual, Volume 2, Chapter 15.
- IBM. IBM PowerVM Virtualization Introduction and Configuration, SG24-7940.
*[ACM]: Association for Computing Machinery *[AMD]: Advanced Micro Devices *[CPU]: Central Processing Unit *[EPT]: Extended Page Table *[GPA]: Guest Physical Address *[HPA]: Host Physical Address *[NPT]: Nested Page Table *[SDM]: Software Developer's Manual *[TLB]: Translation Lookaside Buffer *[VM]: Virtual Machine *[VMCS]: Virtual Machine Control Structure *[VPID]: Virtual Processor Identifier *[VT]: Virtualization Technology
*[APM]: Architecture Programmer's Manual *[OS]: Operating System
Footnotes
-
라이브 마이그레이션live migration이란 VM을 종료하지 않고 실행 중인 상태 그대로 다른 물리 서버로 이동시키는 기술이다. VM의 메모리 페이지를 점진적으로 복사하는 사전 복사pre-copy 방식이 가장 널리 사용된다. — Clark, C. et al. (2005) 'Live Migration of Virtual Machines', Proceedings of NSDI. ↩
-
Popek과 Goldberg의 가상화 정리(1974)는 ISA가 효율적으로 가상화 가능한 충분조건을 제시했다. 모든 민감한 명령어가 특권 명령어의 부분집합이면, 단순한 Trap-and-Emulate로 VMM을 구현할 수 있다. — Popek, G. J. and Goldberg, R. P. (1974) 'Formal Requirements for Virtualizable Third Generation Architectures', Communications of the ACM, 17(7), pp.412-421. ↩
-
민감한 명령어란 시스템의 상태를 변경하거나(제어 민감control-sensitive), 하드웨어 구성에 따라 동작이 달라지는(동작 민감behavior-sensitive) 명령어를 말한다. ↩
-
이진 변환binary translation은 게스트의 기계어 코드를 실행 전에 스캔하여, 가상화를 방해하는 명령어를 하이퍼바이저 호출이나 안전한 대체 코드로 동적 치환하는 기법이다. VMware가 1999년 x86 가상화에 이 방식을 최초로 상용화했다. — Adams, K. and Agesen, O. (2006) 'A Comparison of Software and Hardware Techniques for x86 Virtualization', ASPLOS XII. ↩
-
반가상화para-virtualization에서 접두어 "para-"는 "alongside(곁에)"를 의미하며, 완전한 하드웨어 시뮬레이션이 아닌 하이퍼바이저와의 협력을 통해 가상화를 달성한다는 뜻이다. Xen 프로젝트(2003)가 이 개념을 대중화했다. — Barham, P. et al. (2003) 'Xen and the Art of Virtualization', SOSP '03. ↩
-
하이퍼콜(hypercall)은 게스트 OS가 하이퍼바이저에 서비스를 요청하는 명시적 인터페이스다. Intel VT-x에서는
VMCALL, ARM에서는HVC(Hypervisor Call) 명령어로 트리거된다. — Intel SDM Volume 3, Chapter 24; ARM Architecture Reference Manual, Chapter D1. ↩ -
VT-x(Virtualization Technology for x86)는 Intel이 2005년 Pentium 4(Prescott)부터 도입한 하드웨어 가상화 확장이다.
VMXON/VMXOFF로 VMX(Virtual Machine Extensions) 모드를 활성화/비활성화하고,VMLAUNCH/VMRESUME으로 게스트를 실행한다. — Intel SDM Volume 3, Chapter 23 "Introduction to Virtual Machine Extensions". ↩ -
AMD-V(AMD Virtualization, 코드명 Pacifica)는 AMD가 2006년 Athlon 64부터 도입한 하드웨어 가상화 확장이다. Intel VT-x와 유사한 기능을 제공하며, SVM(Secure Virtual Machine) 확장이라고도 불린다. — AMD64 APM Volume 2, Chapter 15. ↩
-
VM Exit란 게스트 실행 중 하이퍼바이저의 개입이 필요한 이벤트가 발생했을 때, CPU가 비루트 모드에서 루트 모드로 전환하는 동작이다. 반대로 VM Entry는 하이퍼바이저에서 게스트로 복귀하는 동작이다. VM Exit/Entry의 비용은 약 500
2,000 사이클이다. — Intel SDM Volume 3, Chapter 2527. ↩ -
VMCS(Virtual Machine Control Structure)는 Intel VT-x에서 VM의 상태와 전환 조건을 저장하는 4KB 크기의 자료구조다. 게스트 상태 영역, 호스트 상태 영역, VM Exit 제어 필드 등을 포함한다. — Intel SDM Volume 3, Chapter 24. ↩
-
VMCB(Virtual Machine Control Block)는 AMD-V에서 Intel의 VMCS에 대응하는 자료구조다. — AMD64 APM Volume 2, §15.5. ↩
-
EPT(Extended Page Table)는 Intel이 Nehalem(2008년)부터 도입한 2단계 주소 변환 기술이다. GPA→HPA 변환을 하드웨어가 자동으로 수행하여, 섀도우 페이지 테이블의 복잡성과 성능 비용을 제거한다. — Intel SDM Volume 3, Chapter 28 "VMX Support for Address Translation". ↩
-
NPT(Nested Page Table)는 AMD가 Barcelona(2007년)부터 도입한 2단계 주소 변환 기술이다. Intel의 EPT와 동일한 기능을 제공하며, RVI(Rapid Virtualization Indexing)라고도 불린다. — AMD64 APM Volume 2, §15.25. ↩
-
섀도우 페이지 테이블shadow page table은 하드웨어 2단계 변환이 없던 시절, 하이퍼바이저가 GVA→HPA 매핑을 직접 유지하던 소프트웨어 기법이다. 게스트의 페이지 테이블 변경을 하이퍼바이저가 실시간으로 추적하여 섀도우 테이블에 반영해야 하므로, 구현이 복잡하고 VM Exit가 빈번하게 발생했다. — Waldspurger, C. A. (2002) 'Memory Resource Management in VMware ESX Server', OSDI '02. ↩
-
VPID(Virtual Processor Identifier)는 Intel VT-x에서 TLB 항목에 가상 프로세서 식별자를 태깅하는 기능이다. PCID가 프로세스 간 TLB 공유를 가능하게 하듯, VPID는 VM 간 TLB 공유를 가능하게 하여 VM Exit/Entry 시 TLB 플러시를 회피한다. — Intel SDM Volume 3, §28.1. ↩
-
리눅스 네임스페이스(namespace)는 프로세스 그룹에 시스템 자원(PID, 네트워크, 파일 시스템 등)의 격리된 뷰를 제공하는 커널 기능이다.
PID,NET,MNT,UTS,IPC,USER,CGROUP등 7가지 네임스페이스가 있다. —man 7 namespaces. ↩ -
cgroup(control group)은 프로세스 그룹의 CPU, 메모리, I/O, 네트워크 등 자원 사용량을 제한하고 모니터링하는 리눅스 커널 기능이다. 네임스페이스가 "무엇을 볼 수 있는가"를 제어한다면, cgroup은 "얼마나 사용할 수 있는가"를 제어한다. —
Documentation/admin-guide/cgroup-v2.rst. ↩