CPU의 코어 하나는 한 번에 하나의 프로세스만 실행할 수 있습니다. 그런데 실행해야 할 프로세스는 수십, 수백 개에 달합니다. 이 한정된 CPU 자원을 여러 프로세스에 배분하는 결정을 내리는 것이 스케줄러(scheduler)의 역할입니다. 이 글에서는 스케줄링이 왜 필요한지, 어떤 기준으로 판단하는지, 어떤 알고리즘이 있는지, 그리고 리눅스에서는 이를 어떻게 구현하는지를 살펴봅니다.
왜 스케줄링이 필요한가
프로세서보다 프로세스가 많은 상황에서는 어떤 프로세스가 CPU를 사용하고 어떤 프로세스가 기다릴지를 결정해야 한다. 이 결정을 내리는 커널 내부의 메커니즘이 CPU 스케줄러다.
스케줄링이 없다면 하나의 프로세스가 CPU를 독점하고 나머지는 무한정 기다려야 한다. 특히 프로세스는 실행 도중에 입출력 요청, 메모리 접근, 네트워크 대기 등으로 빈번하게 CPU를 사용하지 않는 구간이 생기는데, 그 시간에 다른 프로세스를 실행하면 CPU 이용률을 크게 높일 수 있다. 스케줄러는 바로 이런 결정을 빠르고 합리적으로 내려 시스템 전체의 효율을 극대화하는 역할을 한다.
I/O 바운드와 CPU 바운드
스케줄링을 이해하기 위해서는 프로세스의 성격을 구분할 필요가 있다. 프로세스는 CPU를 사용하는 구간(CPU 버스트CPU burst)과 입출력을 기다리는 구간(I/O 버스트I/O burst)을 번갈아 반복하는데, 어떤 구간이 더 지배적인지에 따라 두 유형으로 나뉜다.
- I/O 바운드 프로세스I/O-bound process는 CPU 연산보다 입출력 대기에 더 많은 시간을 소비한다. 텍스트 에디터나 웹 브라우저처럼 사용자 입력을 기다리는 대화형interactive 프로세스가 대표적이다. CPU 버스트가 짧고 빈번하며, 빠른 응답 시간이 중요하다.
- CPU 바운드 프로세스CPU-bound process는 입출력보다 CPU 연산에 더 많은 시간을 소비한다. 과학 시뮬레이션이나 영상 인코딩처럼 연산 집약적인 프로세스가 이에 해당한다. CPU 버스트가 길고 드물며, 높은 처리량throughput이 중요하다.
좋은 스케줄러는 이 두 유형의 프로세스가 공존하는 환경에서 I/O 바운드 프로세스에는 빠른 응답을, CPU 바운드 프로세스에는 충분한 연산 시간을 보장해야 한다.
스케줄링의 기준
스케줄링 알고리즘의 성능을 평가하는 기준은 여러 가지가 있으며, 상황에 따라 어떤 기준을 우선시할지가 달라진다.
- CPU 이용률CPU utilization은 CPU가 유휴idle 상태가 아닌 시간의 비율이다. CPU가 놀지 않고 가능한 한 많이 일하도록 하는 것이 이 기준의 목표다.
- 처리량throughput은 단위 시간당 완료되는 프로세스의 수다. 같은 시간 내에 더 많은 작업을 끝내는 스케줄러가 처리량 측면에서 우수하다.
- 반환 시간turnaround time은 프로세스가 제출된 시점부터 완료될 때까지 걸린 전체 시간이다. 대기 시간, 실행 시간, 입출력 시간을 모두 포함한다.
- 대기 시간waiting time은 프로세스가 실행 대기열ready queue에서 대기한 시간의 총합이다. 스케줄링 알고리즘이 직접적으로 영향을 미치는 지표다.
- 응답 시간response time은 요청이 제출된 시점부터 첫 번째 응답이 시작될 때까지의 시간이다. 대화형 시스템에서 특히 중요한 기준이다.
일반적으로 CPU 이용률과 처리량은 최대화하고, 반환 시간·대기 시간·응답 시간은 최소화하는 것이 바람직하다. 하지만 이 기준들은 서로 상충trade-off하는 경우가 많아, 스케줄링 알고리즘의 설계는 결국 어떤 기준에 얼마만큼의 가중치를 두느냐의 문제가 된다.
선점 스케줄링과 비선점 스케줄링
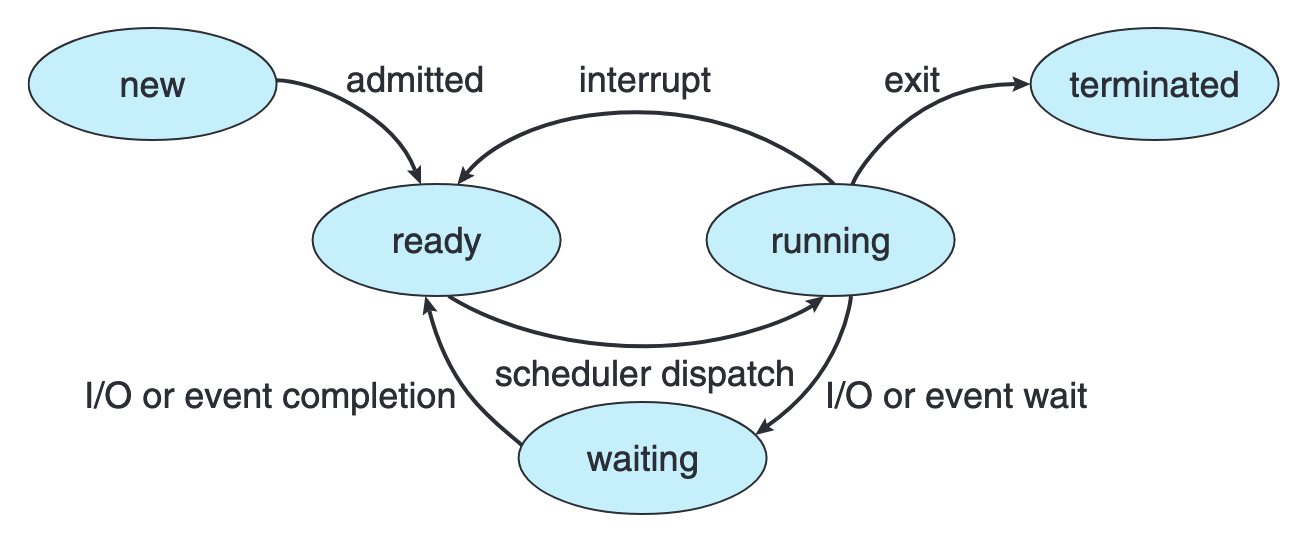
스케줄러가 결정을 내리는 시점은 크게 네 가지다.
- 프로세스가 running 상태에서 waiting 상태로 전이할 때 (I/O 요청 등)
- 프로세스가 running 상태에서 ready 상태로 전이할 때 (타이머 인터럽트 등)
- 프로세스가 waiting 상태에서 ready 상태로 전이할 때 (I/O 완료 등)
- 프로세스가 종료될 때
이 네 시점에서의 동작 방식에 따라 스케줄링은 두 가지로 분류된다.
- 비선점 스케줄링non-preemptive scheduling에서는 1번과 4번 상황에서만 스케줄링이 발생한다. 즉 프로세스가 자발적으로 CPU를 내놓거나(I/O 요청, 종료) 할 때만 다른 프로세스가 CPU를 받는다. 한번 CPU를 할당받은 프로세스는 스스로 양보하기 전까지 중단되지 않으므로 구현이 단순하지만, CPU 버스트가 긴 프로세스가 CPU를 오래 독점할 위험이 있다.1
- 선점 스케줄링preemptive scheduling에서는 네 가지 상황 모두에서 스케줄링이 발생할 수 있다. 특히 2번(타이머 인터럽트)과 3번(I/O 완료 후 우선순위 비교)에서 커널이 실행 중인 프로세스를 강제로 중단하고 다른 프로세스에게 CPU를 넘길 수 있다. 대부분의 현대 운영체제는 선점 스케줄링을 사용하는데, 이는 단일 프로세스의 CPU 독점을 방지하고 대화형 프로세스의 응답 시간을 보장하기 위해서다. 다만 선점 스케줄링은 공유 자원에 대한 동기화synchronization 문제를 수반한다.2
스케줄링 알고리즘
다양한 스케줄링 알고리즘이 존재하며, 각각 다른 기준에 최적화되어 있다. 여기서는 대표적인 알고리즘의 핵심 아이디어를 간략하게 소개한다.
FCFS
FCFS(First-Come First-Served, 선입 선처리)는 가장 단순한 알고리즘으로, 먼저 도착한 프로세스가 먼저 CPU를 할당받는다. 비선점 방식이며, 구현이 간단하지만 CPU 버스트가 긴 프로세스가 앞에 오면 뒤의 짧은 프로세스들이 오래 기다리는 호위 효과convoy effect3가 발생할 수 있다.


0 ─── P1 ─── 24 ── P2 ── 27 ── P3 ── 30
대기 시간: P1 = 0, P2 = 23, P3 = 25 → 평균 = 16.0 반환 시간: P1 = 24, P2 = 26, P3 = 28 → 평균 = 26.0
SJF
SJF(Shortest Job First, 최단 작업 우선)는 다음 CPU 버스트가 가장 짧은 프로세스를 먼저 실행한다. 평균 대기 시간을 최소화하는 것이 수학적으로 증명된 최적 알고리즘이지만, 다음 CPU 버스트 길이를 미리 알 수 없다는 근본적인 한계가 있다. 실제로는 과거의 CPU 버스트 길이를 기반으로 지수적 평균exponential averaging을 이용해 추정한다.4


0 ── P1 ── 6 ── P4 ── 9 ── P3 ── 16 ── P2 ── 24
대기 시간: P1 = 0, P2 = 14, P3 = 5, P4 = 1 → 평균 = 5.0 반환 시간: P1 = 6, P2 = 22, P3 = 12, P4 = 4 → 평균 = 11.0 P1 완료 후 대기열 {P2, P3, P4} 중 버스트가 가장 짧은 P4를 선택한다.
우선순위 스케줄링
우선순위 스케줄링priority scheduling은 각 프로세스에 우선순위를 부여하고, 우선순위가 가장 높은 프로세스를 먼저 실행한다. SJF도 "다음 CPU 버스트 길이"를 우선순위로 사용하는 우선순위 스케줄링의 특수한 경우라고 볼 수 있다. 치명적인 문제는 기아starvation5인데, 우선순위가 낮은 프로세스가 우선순위가 높은 프로세스에 밀려 무한정 기다리게 될 수 있다. 이를 해결하기 위해 대기 시간이 길어질수록 우선순위를 점진적으로 올려주는 에이징(aging) 기법을 사용한다.


0 P1 1 P2 2 P1 4 P5 9 P1 16 P3 18 P4 19
대기 시간: P1 = 6, P2 = 0, P3 = 14, P4 = 15, P5 = 0 → 평균 = 7.0
시각 1에 P2(우선순위 1)가 도착하면 P1(우선순위 3)을 선점한다. 시각 2에 P2가 완료되면 대기열에는 P1(우선순위 3)과 P3(우선순위 4)가 있으므로 P1이 다시 실행된다. 시각 4에 P5(우선순위 2)가 도착하면 P1(우선순위 3)보다 높으므로 P1을 선점하고 실행된다. P3, P4는 높은 우선순위 프로세스에 밀려 오래 대기하는 기아 문제가 발생한다. 이를 해결하기 위한 방법이 에이징으로, 대기 시간이 증가할수록 우선순위를 점진적으로 상향 조정한다.
라운드 로빈
라운드 로빈Round Robin(RR)은 선점 스케줄링의 대표적인 알고리즘으로, 각 프로세스에 일정한 시간 할당량time quantum(타임 슬라이스)을 부여하고 그 시간이 지나면 강제로 프로세스를 전환한다. FCFS에 선점을 더한 것으로 볼 수 있으며, 타임 퀀텀의 크기가 성능을 좌우한다. 타임 퀀텀이 너무 크면 FCFS와 다를 바 없고, 너무 작으면 컨텍스트 스위치 오버헤드가 지배적이 된다.6


0 P1 4 P2 7 P3 10 P1 14 P1 18 P1 22 P1 26 P1 30
대기 시간: P1 = 6, P2 = 4, P3 = 7 → 평균 = 5.67 반환 시간: P1 = 30, P2 = 7, P3 = 10 → 평균 = 15.67 FCFS 대비 P2, P3의 대기 시간이 크게 감소했다. 타임 퀀텀이 무한대로 가면 FCFS와 동일하고 컨텍스트 스위치가 최소가 되며, 타임 퀀텀이 0으로 가면 프로세서 공유 효과가 있지만 컨텍스트 스위치 오버헤드가 지배적이 된다. 경험적으로 CPU 버스트의 80%가 타임 퀀텀 이내여야 한다.
다단계 큐
다단계 큐multilevel queue는 프로세스를 성격에 따라 여러 개의 큐로 분류하고, 각 큐마다 다른 스케줄링 알고리즘을 적용하는 방식이다. 예를 들어, 전위foreground(대화형) 프로세스에는 라운드 로빈을, 후위background(배치) 프로세스에는 FCFS를 적용할 수 있다. 큐 간의 스케줄링은 보통 고정 우선순위로 처리하거나, 각 큐에 CPU 시간의 일정 비율을 할당하는 방식을 사용한다.


다단계 피드백 큐multilevel feedback queue는 여기서 한 걸음 더 나아가 프로세스가 큐 사이를 이동할 수 있도록 한다. CPU 버스트를 오래 사용한 프로세스는 하위 큐로 내려가고, 대기 시간이 긴 프로세스는 상위 큐로 올라간다(에이징). 이 방식은 가장 범용적인 스케줄링 알고리즘이지만, 설계해야 할 매개변수(큐의 수, 각 큐의 알고리즘, 승격/강등 기준 등)가 많아 복잡하다.
Linux의 스케줄링 아키텍처
리눅스는 앞서 설명한 여러 알고리즘의 장점을 조합하기 위해 클래스 기반 디스패치class-based dispatch 모델을 채택하고 있다. 각 스케줄링 클래스는 struct sched_class라는 공통 인터페이스를 구현하며, 커널은 우선순위 순서대로 클래스를 순회하며 실행할 태스크를 선택한다.


태스크를 선택할 때(__pick_next_task()), 커널은 stop → deadline → rt → fair → ext → idle 순서로 각 클래스의 pick_next_task()를 호출하고, 실행 가능한 태스크를 반환하는 첫 번째 클래스의 결과를 사용한다.7 따라서 실시간 태스크가 하나라도 존재하면 일반 태스크보다 항상 먼저 실행된다.
우선순위 체계
리눅스 내부의 우선순위는 0부터 139까지의 정수로 표현된다.


099는 실시간real-time 우선순위 영역으로, 139는 일반 프로세스 영역으로, 전통적인 SCHED_FIFO와 SCHED_RR 정책이 사용한다. 숫자가 작을수록 우선순위가 높다. 100nice 값(-20~+19)에 대응한다. nice 0은 우선순위 120에 해당하며, 이것이 기본값이다.8 SCHED_DEADLINE 태스크는 실시간 태스크보다도 높은 우선순위를 가지며, stop 태스크는 시스템에서 가장 높은 우선순위를 가진다.
__schedule(): 스케줄링의 핵심
스케줄링의 모든 경로는 결국 kernel/sched/core.c에 정의된 __schedule() 함수로 수렴한다. 이 함수는 타이머 인터럽트, 시스템 호출, 입출력 완료 등의 시점에서 호출되며, 다음과 같은 일을 한다(Linux v6.19 기준).
- 현재 CPU의 런큐(runqueue)9를 잠근다.
- 현재 실행 중인 태스크의 상태를 확인하고, 필요하면 런큐에서 제거한다(sleeping 전환 등).
- 스케줄링 클래스를 우선순위 순서대로 순회하며 다음에 실행할 태스크를 선택한다.
- 선택된 태스크가 현재 태스크와 다르면 컨텍스트 스위치를 수행한다.
- 런큐의 잠금을 해제한다.
이 과정에서 스케줄러가 어떤 태스크를 선택하느냐는 순전히 각 스케줄링 클래스의 구현에 달려 있다. 일반 프로세스의 대부분을 담당하는 fair 클래스의 구현은 CFS 포스트에서 자세히 다룬다.
출처
- Silberschatz, A., Galvin, P.B. and Gagne, G. (2018) Operating System Concepts. 10th edn. Hoboken: Wiley.
- Arpaci-Dusseau, R.H. and Arpaci-Dusseau, A.C. (2023) Operating Systems: Three Easy Pieces. 1.10 edn. Arpaci-Dusseau Books.
- Love, R. (2010) Linux Kernel Development. 3rd edn. Upper Saddle River: Addison-Wesley.
- Bovet, D.P. and Cesati, M. (2005) Understanding the Linux Kernel. 3rd edn. Sebastopol: O'Reilly.
- Tanenbaum, A.S. and Bos, H. (2023) Modern Operating Systems. 5th edn. Hoboken: Pearson.
- Linux kernel source v6.19 —
kernel/sched/core.c,kernel/sched/sched.h,kernel/sched/fair.c.
*[CPU]: Central Processing Unit *[FCFS]: First-Come First-Served *[SJF]: Shortest Job First
Footnotes
-
협력적 스케줄링cooperative scheduling이라고도 불린다. Windows 3.1, Mac OS 9 이전 버전이 이 방식을 사용했다. 하나의 프로그램이 무한 루프에 빠지면 시스템 전체가 멈추는 문제가 있었다. ↩
-
프로세스 A가 공유 데이터를 수정하는 도중에 선점되어 프로세스 B가 같은 데이터를 읽으면, B는 불완전한 상태의 데이터를 보게 된다. 이를 경쟁 조건race condition이라 하며, 뮤텍스(mutex)나 세마포어(semaphore) 같은 동기화 메커니즘으로 방지한다. ↩
-
호위 효과란 CPU 버스트가 긴 프로세스 하나가 CPU를 오래 차지하면서, 뒤에 줄 선 짧은 프로세스들의 대기 시간이 연쇄적으로 길어지는 현상이다. ↩
-
다음 CPU 버스트 추정은 ()으로 계산된다. 은 실제 번째 CPU 버스트 길이, 은 그 추정값이다. 가 1에 가까우면 최근 값에 더 큰 가중치를 준다. ↩
-
기아란 프로세스가 필요한 자원을 무한정 기다리는 상태를 말한다. 우선순위 스케줄링에서는 우선순위가 높은 프로세스가 끊임없이 도착하면 낮은 프로세스가 영원히 실행되지 못할 수 있다. ↩
-
일반적으로 타임 퀀텀은 10~100ms 범위로 설정되며, 컨텍스트 스위치 비용(보통 10μs 이하)에 비해 충분히 크게 정한다. ↩
-
ext_sched_class는 링커 섹션 배치상fair와idle사이에 위치한다(vmlinux.lds.h참고).CONFIG_SCHED_CLASS_EXT활성 시,for_each_active_class매크로가scx_switched_all()이 참이면fair를 건너뛰어ext가 모든 일반 태스크를 처리한다. 즉ext는fair보다 낮은 우선순위에 위치하되, BPF 스케줄러가 전환되면fair를 대체하는 구조다. ↩ -
nice값에서 커널 내부 우선순위로의 변환은prio = MAX_RT_PRIO + nice + 20이다.MAX_RT_PRIO는 100이므로,nice0일 때prio = 100 + 0 + 20 = 120이 된다.include/linux/sched/prio.h를 참고하며 된다. ↩ -
런큐(runqueue)는 각 CPU 코어마다 하나씩 존재하는
struct rq구조체로, 해당 CPU에서 실행 대기 중인 태스크를 관리한다. 스케줄링 클래스별 서브큐(cfs_rq,rt_rq,dl_rq등)를 포함하며, 현재 실행 중인 태스크에 대한 포인터도 가지고 있다.kernel/sched/sched.h를 참고하면 된다. ↩