틱택토, 체스, 바둑 같은 2인 제로섬 게임에서 AI는 어떻게 최선의 수를 찾을까요? 미니맥스_Minimax_ 알고리즘은 "상대방도 나처럼 합리적으로 플레이한다"는 가정 하에, 게임 트리를 끝까지 탐색하여 최악의 상황에서도 최선인 수를 계산하는 알고리즘입니다. 여기에 Alpha-Beta Pruning을 더하면 결과를 바꾸지 않으면서 탐색량을 극적으로 줄일 수 있고, Expectimax를 적용하면 주사위나 카드 같은 확률적 요소가 있는 게임까지 다룰 수 있습니다. 이 글에서는 적대적 탐색의 핵심인 이 세 가지 알고리즘을 차례로 살펴봅니다.
미니맥스 알고리즘과 적대적 탐색
적대적 탐색이란?
출발지에서 목적지로 향하는 최적의 경로를 찾는 일반적인 탐색 문제에서는 에이전트 혼자 목표를 향해 나아가지만, 게임에서는 나의 이익을 최소화하려는 상대방이 존재한다. 이처럼 이해관계가 상충하는 환경에서의 탐색을 적대적 탐색Adversarial Search이라고 합니다.
적대적 탐색의 대표적인 무대는 2인 제로섬 게임Two-Player Zero-Sum Game이다. 한 쪽이 이기면 다른 쪽은 반드시 지는 구조이기 때문에 양측의 효용 합은 항상 0이며, 이런 게임에서는 "상대방이 최선을 다할 때, 나도 최선을 다하면 어떤 결과에 도달하는가?"를 알아야 이길 가능성이 생긴다. 미니맥스 알고리즘은 바로 이 질문을 해결한다.
미니맥스 알고리즘
핵심 아이디어
미니맥스에서는 두 플레이어를 MAX와 MIN으로 부른다. MAX는 게임의 결과값Utility을 최대화하려 하고, MIN은 이를 최소화하려 한다. 게임이 MAX → MIN → MAX → MIN → … 순서로 진행될 때, 각 상태의 minimax 값은 다음과 같이 재귀적으로 정의된다.
게임의 끝Terminal State에 도달하면 실제 결과(승리/패배/무승부)가 숫자로 결정된다. 거기서부터 거슬러 올라오면서, MAX의 차례인 노드에서는 자식 중 가장 큰 값을, MIN의 차례인 노드에서는 자식 중 가장 작은 값을 선택한다. 이렇게 루트까지 값을 역전파하면 MAX가 취해야 할 최적의 수가 결정된다.


위 그림에서 △ 노드는 MAX의 차례, ▽ 노드는 MIN의 차례를 의미한다. 말단 노드의 효용값(3, 12, 8, 2, 4, 6, 14, 5, 2)에서 출발하여, MIN은 각각 최솟값(3, 2, 2)을 고르고, MAX는 그 중 최댓값(3)을 선택한다. 따라서 MAX의 최적 행동은 이 된다.
알고리즘의 성질
미니맥스 알고리즘의 주요 성질은 다음과 같다.
- 완전성_Completeness_: 게임 트리가 유한하면 반드시 답을 찾는다.
- 최적성_Optimality_: MIN이 합리적으로 행동한다는 가정 하에 최적이다. 즉, 상대가 실수하지 않아도 나올 수 있는 최선의 결과를 보장한다.
- 시간 복잡도: 분기 계수(한 상태에서 가능한 행동 수)가 이고 탐색 깊이가 일 때 미니맥스 알고리즘의 시간 복잡도는 이다.
- 공간 복잡도: DFS 방식으로 탐색하기 때문에 공간 복잡도는 이다.
체스의 경우 , 이므로 미니맥스 방식을 사용한다면 개의 노드를 탐색해야 한다. 현실적으로 불가능한 규모이기 때문에, 문제를 해결하기 위해 알파-베타 가지치기Alpha-Beta Pruning가 등장한다.
의사코드
\begin{algorithm}
\caption{미니맥스 탐색}
\begin{algorithmic}
\Ensure 하나의 행동
\Function{Minimax-Search}{$game, state$}
\State $player \gets game.\text{To-Move}(state)$
\State $value, move \gets \text{Max-Value}(game, state)$
\Return $move$
\EndFunction
\Function{Max-Value}{$game, state$} \Comment{$(utility, move)$ 쌍을 반환}
\If{$game.\text{Is-Terminal}(state)$}
\Return $game.\text{Utility}(state, player),\ null$
\EndIf
\State $v \gets -\infty$
\ForAll{$a \in game.\text{Actions}(state)$}
\State $v_2, a_2 \gets \text{Min-Value}(game, game.\text{Result}(state, a))$
\If{$v_2 > v$}
\State $v, move \gets v_2, a$
\EndIf
\EndFor
\Return $v, move$
\EndFunction
\Function{Min-Value}{$game, state$} \Comment{$(utility, move)$ 쌍을 반환}
\If{$game.\text{Is-Terminal}(state)$}
\Return $game.\text{Utility}(state, player),\ null$
\EndIf
\State $v \gets +\infty$
\ForAll{$a \in game.\text{Actions}(state)$}
\State $v_2, a_2 \gets \text{Max-Value}(game, game.\text{Result}(state, a))$
\If{$v_2 < v$}
\State $v, move \gets v_2, a$
\EndIf
\EndFor
\Return $v, move$
\EndFunction
\end{algorithmic}
\end{algorithm}
Alpha-Beta Pruning
불필요한 탐색 제거하기
미니맥스 알고리즘의 시간 복잡도 은 게임 트리의 모든 노드를 방문하기 때문에 발생한다. 하지만 실제로는 결과에 영향을 미치지 않는 상황이 상당히 많이 존재한다. 알파-베타 가지치기Alpha-Beta Pruning는 이런 가지를 잘라내어Prune 탐색량을 줄이면서도 미니맥스 알고리즘과 동일한 결과를 보장하는 최적화 기법이다.
다음 선택지가 현재까지의 최선보다 확실히 못하면, 더 볼 필요가 없다. 이를 위해 두 개의 경계값을 유지한다.
- : MAX가 지금까지 확보한 최선의 값 (하한). MAX는 최소한 이만큼은 받을 수 있다.
- : MIN이 지금까지 확보한 최선의 값 (상한). MIN은 결과를 최대 이만큼 억제할 수 있다.
탐색 과정에서 가 되면, 현재 가지의 나머지 부분은 절대로 선택되지 않으므로 즉시 잘라낸다Cutoff.
가지치기가 일어나는 두 가지 상황
- MAX의 차례에서 (Beta Cutoff): 현재 노드의 값 가 갱신되어 가 되면, MIN인 부모 입장에서 이 가지는 이미 너무 좋은(큰) 값이므로 절대 선택하지 않고 나머지 자식 노드 탐색을 건너뛴다.
- MIN의 차례에서 (Alpha Cutoff): 현재 노드의 값 가 갱신되어 가 되면, MAX인 부모 입장에서 이 가지는 이미 너무 나쁜(작은) 값이므로 절대 선택하지 않고 마찬가지로 나머지 탐색을 건너뛴다.
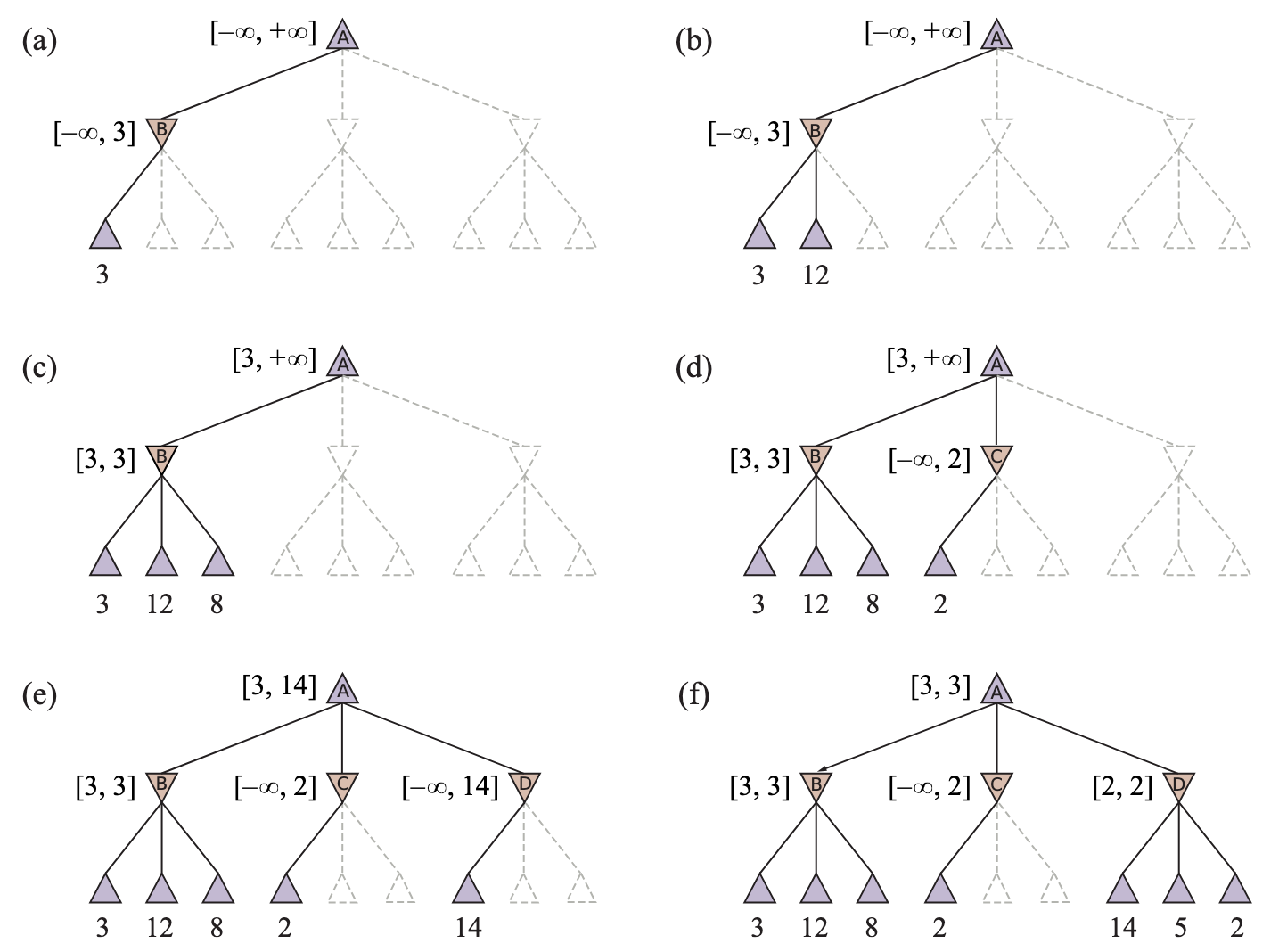
효과와 한계
Alpha-Beta Pruning의 효과는 노드를 어떤 순서로 방문하느냐에 크게 좌우된다. 가지치기가 전혀 일어나지 않는 최악의 경우, 시간 복잡도는 여전히 으로 기본적인 미니맥스 알고리즘과 동일하다. 하지만 완벽한 순서로 노드를 방문하면 시간 복잡도가 까지 떨어지는데, 이는 같은 시간에 두 배 깊이까지 탐색할 수 있다는 뜻이다. 실전에서는 이동 순서 휴리스틱을 적용하여 좋은 수를 먼저 탐색하도록 유도하며, 평균적으로 분기 계수가 로 감소하는 효과를 얻는다.
의사코드
\begin{algorithm}
\caption{알파-베타 가지치기}
\begin{algorithmic}
\Ensure 하나의 행동
\Function{Alpha-Beta-Search}{$game, state$}
\State $player \gets game.\text{To-Move}(state)$
\State $value, move \gets \text{Max-Value}(game, state, -\infty, +\infty)$
\Return $move$
\EndFunction
\Function{Max-Value}{$game, state, \alpha, \beta$} \Comment{$(utility, move)$ 쌍을 반환}
\If{$game.\text{Is-Terminal}(state)$}
\Return $game.\text{Utility}(state, player),\ null$
\EndIf
\State $v \gets -\infty$
\ForAll{$a \in game.\text{Actions}(state)$}
\State $v_2, a_2 \gets \text{Min-Value}(game, game.\text{Result}(state, a), \alpha, \beta)$
\If{$v_2 > v$}
\State $v, move \gets v_2, a$
\State $\alpha \gets \max(\alpha, v)$
\EndIf
\If{$v \geq \beta$}
\Return $v, move$ \Comment{베타 가지치기}
\EndIf
\EndFor
\Return $v, move$
\EndFunction
\Function{Min-Value}{$game, state, \alpha, \beta$} \Comment{$(utility, move)$ 쌍을 반환}
\If{$game.\text{Is-Terminal}(state)$}
\Return $game.\text{Utility}(state, player),\ null$
\EndIf
\State $v \gets +\infty$
\ForAll{$a \in game.\text{Actions}(state)$}
\State $v_2, a_2 \gets \text{Max-Value}(game, game.\text{Result}(state, a), \alpha, \beta)$
\If{$v_2 < v$}
\State $v, move \gets v_2, a$
\State $\beta \gets \min(\beta, v)$
\EndIf
\If{$v \leq \alpha$}
\Return $v, move$ \Comment{알파 가지치기}
\EndIf
\EndFor
\Return $v, move$
\EndFunction
\end{algorithmic}
\end{algorithm}
Expectimax
확정적 게임에서 확률적 게임으로
Minimax와 Alpha-Beta Pruning은 양측 플레이어의 행동이 게임 상태를 완전히 결정하는 확정적 게임Deterministic Game을 전제로 한다. 하지만 주사위를 굴리는 백개먼(Backgammon)이나 카드를 섞는 포커처럼, 확률적 요소Chance Element가 개입하는 게임에서는 미래 상태가 확실하지 않다.
이런 게임을 다루기 위해 MAX 노드와 MIN 노드 사이에 확률 노드Chance Node가 끼어들어 각 결과가 일어날 확률에 따른 기대값(Expected Value)을 계산하는 것이 바로 Expectimax 알고리즘이다.
기대 효용값의 계산
확률 노드에서의 값은 가능한 각 결과의 minimax 값에 그 결과가 발생할 확률을 곱한 다음 더한다.
여기서 는 확률 이벤트 가 발생할 확률이고, 는 해당 이벤트가 발생했을 때의 결과 상태다.
미니맥스 알고리즘과 비교하면 핵심 차이는 명확하다. 미니맥스 알고리즘에서 MIN은 "최악의 경우"를 선택하지만, Expectimax의 확률 노드는 "평균적인 경우"를 계산하기 때문에, Expectimax 알고리즘은 상대가 합리적이지 않거나 환경에 불확실성이 존재할 때 더 현실적인 판단을 내릴 수 있다.
다만 Expectimax에서는 Alpha-Beta Pruning을 그대로 적용할 수 없다. 확률 노드의 값은 모든 자식의 가중 합이기 때문에 하나의 자식 값만으로는 상한이나 하한을 확정할 수 없다. 또한, 효용값의 스케일이 결과에 영향을 미치는데, 미니맥스 알고리즘에서는 효용값의 순서만 중요했지만(단조 변환에 불변), Expectimax에서는 기대값을 계산하므로 효용값의 절대적 크기가 의사결정에 직접 영향을 준다.
출처
- Russell, S.J. and Norvig, P. (2021) Artificial intelligence: a modern approach. 4th edn. Harlow: Pearson. (Chapter 5: Adversarial Search and Games)
- Knuth, D.E. and Moore, R.W. (1975) 'An analysis of alpha-beta pruning', Artificial Intelligence, 6(4), pp. 293–326.
- Kocsis, L. and Szepesvári, C. (2006) 'Bandit based Monte-Carlo planning', in Machine Learning: ECML 2006. Berlin: Springer, pp. 282–293.
- Baier, H. and Winands, M.H.M. (2015) ‘MCTS-Minimax Hybrids’, IEEE Transactions on Computational Intelligence and AI in Games, 7(2), pp. 167–179.