데이터베이스를 설계할 때 중요한 포인트 중 하나는 데이터베이스가 효율적인 검색을 위한 자료구조라는 것을 잊지 않는 것입니다. 그래서 그에 맞는 형태로 빚어내야 하는 거죠. 이번 글에서는 데이터베이스의 형태와 관련된 개념인 분해Decomposition에 대해 알아봅니다.
Decomposition
관계형 데이터베이스를 설계하는 과정에서 관계형 스키마Relation Schema를 생성하는 과정에 초점을 맞춰보자. 이 과정에서 고려해야 할 것은 관계형 스키마를 "좋은 형태"로 빚어내는 것이다. 그렇다면 이 "좋은 형태"란 도대체 무엇인가? 바로 연산 과정에서, 특히 데이터베이스에 정보를 추가하거나 검색할 때 중복하지 않는 형태다. 이러한 "좋은 형태"에는 여러 유형이 있는데, 이들을 정규형Normal Form라고 한다. 만약 관계형 스키마가 "좋은 형태"가 아니라면 그때는 "좋은 형태"의 관계형 스키마만 남도록 기존의 관계형 스키마를 분할해야 하는데, 이 과정을 분해Decomposition라 부른다.
분해의 핵심은 정규형이 아닌 관계형 스키마를 정규형으로 만드는 것이다. 아래 그림은 이를 제대로 수행하지 못한 나쁜 분해의 예시다.
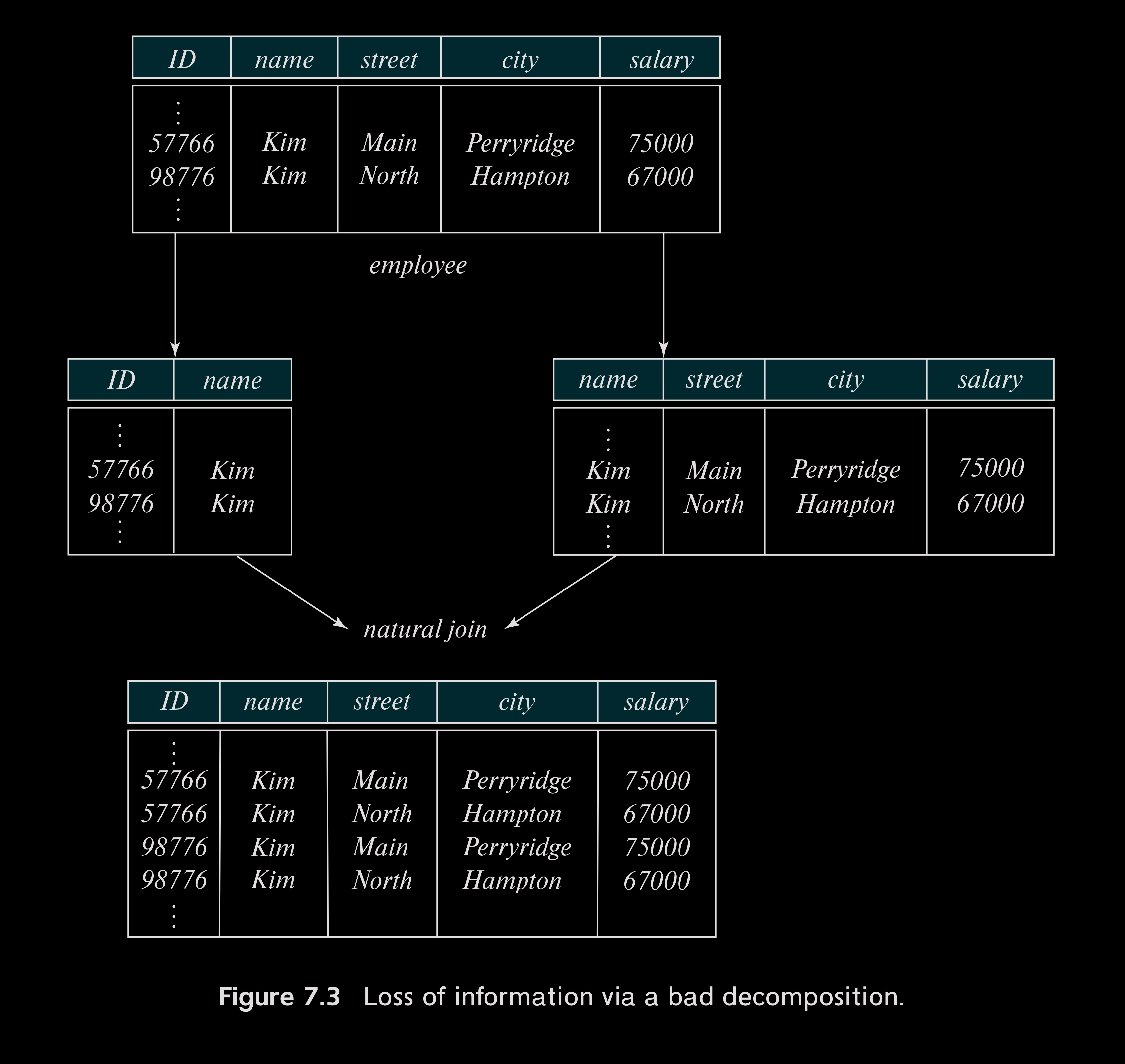
라는 관계형 스키마를 둘로 분해한 다음 내추럴 조인(Natural Join) 연산을 통해 다시 원래대로 합치려 하니 정보를 잘못 섞는 바람에 이름이 으로 같은 두 직원의 정보가 불분명해졌다. 이렇듯 정보의 손실을 야기하는 나쁜 분해를 손실 분해Lossy Decomposition이라 부르며, 이와 반대로 정보의 손실 없이 이루어진 분해를 무손실 분해Lossless Decomposition이라 부른다.
Lossless Decomposition
조금 더 엄밀하게 정의해보자. 를 만족하는 관계형 스키마 , , 에 대하여 을 과 로 대체했을 때 정보의 손실이 일어나지 않는다면, 을 과 로 나누는 그 분해는 무손실 분해이다. 이 정의 다음의 SQL 명령을 실행했을 때 원본인 전체를 쿼리했을 때와 같은 결과가 나와야 한다는 것을 의미한다.
select *
from (select R_1 from r)
natural join
(select R_2 from r)관계 대수Relational Algebra의 측면에서 무손실 분할은 곧 아래와 같은 식이 성립한다는 것과 같다. 이 식은 관계형 스키마가 인 관계 에서 과 에 해당하는 속성만 드러나도록 프로젝트(project)1 연산을 수행한 뒤 그 결과끼리 Join 연산을 수행하면 그 결과가 이 된다는 의미다.
Lossy Decomposition
를 만족하는 관계형 스키마 , , 에 대하여 만약 정보의 손실이 일어나는 손실 분해가 이루어졌다면 SQL과 관계 대수의 결과 모두 원본을 포함한다. 즉, 이다. 더 큰 집합임에도 불구하고 정보의 손실이 일어났다고 정의하는 이유는 위에서 살펴본 사례처럼 일부 속성의 값이 같은 서로 다른 두 데이터를 구분하기 위해 사용했던 정보를 더 이상 활용할 수 없게 되었기 때문이다.
Decomposition & Functional Dependency
함수 종속Functional Dependency을 통해 분해의 손실 여부를 보여줄 수도 있다. 관계 스키마 와 의 함수 종속 집합 에 대하여 함수 종속 혹은 중 최소 하나가 에 존재한다면, 을 과 로 나누는 분해는 손실이 없다. 그리고 이는 곧 가 이나 의 슈퍼키가 된다는 것을 의미하기도 한다. 다만 이를 위해서는 데이터베이스의 모든 제약 조건이 함수 종속으로 표현 가능해야만 한다. 또한 관계형 스키마가 각각 인 관계 에 대하여 이 유지될 때, 가 의 주요 키Primary Key가 되어야 함수 종속이 강제되고, 가 에서 을 참조하는 외래 키Foreign Key가 되어야 과 를 대상으로 내추럴 조인 연산을 수행했을 때 가짜 튜플Spurious Tuple이 생기지 않는다. 이러한 제약 조건은 원본 스키마 의 특성이 분해된 에서도 유지됨을 보장한다. 가 더 세분화되더라도, 의 모든 속성이 하나의 관계에 존재하는 한 이나 에 존재하는 주요 키 제약Primary Key Constraint나 외래 키 제약Foreign Key Constraint는 그 관계에 상속될 것이다.
그래서 분해는 어떻게 해요?
그렇다면 분해는 어떻게 해야 할까? 분해는 정규형으로 해야 한다는 것을 다시금 생각해보자. 정규형에는 다음과 같이 여러 가지 유형이 있다.
- Boyce-Codd Normal Form
- 제3정규형 (3NF)
- 제4정규형 (4NF)
- 제5정규형(5NF)
- Domain-Key Normal Form(예정)
정규형에 따라 분해하는 방법이 다르고 지켜야 할 조건도 다르다. 일부 정규형을 분해하는 과정은 함수 종속 외에도 다치 종속Multivalued Dependency을 활용하기도 한다. 이런 이유로 인해 모든 정규형의 분해 과정을 이 글에서 일일이 추적하기보다는 우선 각각 별도의 글로 다룰 예정이다.
출처
- Silberschatz, A., Korth, H.F. and Sudarshan, S. (2020) Database system concepts. Seventh edition. New York, NY: McGraw-Hill
Footnotes
-
관계 대수에서 프로젝션(Projection)은 관계에서 특정 속성(열)만 추출하는 연산이다. 기호는 그리스 대문자 파이()를 사용하며, 은 관계 에서 에 해당하는 속성만 남긴 결과를 의미한다. ↩